Here is a simple little matlab demo script of how to count items using the command sparse. Counting the occurrences of items is a frequently performed task in vision and not many people know that sparse can do this. Remember, if you're going to be a matlab jedi do not write for loops:
I am using github's gists to embed this code in style. Github lets me choose the language, highlights the syntax accordingly, and the snippet is its own repository!
Friday, March 25, 2011
Thursday, March 24, 2011
Computer Vision is Artificial Intelligence
Computer vision is a diverse field and its researchers have multifaceted interests and aspirations. It should not be surprising that no two vision researchers think about the field in the same way. Different academic backgrounds foster alternative and potentially incommensurable interpretations. It is as if W.V.O Quine's thesis that no observation can be "theory-independent" directly applies to vision: a researcher in computer vision cannot uphold a view on his own field that is objective and independent of their own predispositions, upbringing, and educational program. While I cannot speak clearly about the long-term goals of the entire body researchers in vision, today I would like discuss my own take on computer vision. I do not offer the world an objective account of why computer vision intrigues me, but by sharing with the world the reasons why I find vision exciting, perhaps together we can break the boundaries of machine intelligence.



Any application which calls for automated analysis of images requires vision. A robot, if it is to be successful interacting with the world and performing useful tasks, needs to perceive the external world and organize it. While some see vision as just one small piece of the "Robotics Challenge" (build a robot and make it do cool stuff), it totally unclear to me where to draw the boundary between low-level pixel analysis and high-level cognitive scene understanding. Over the years, I have been thinking more and more about this problem, and I've convinced myself that the interesting part of vision is precisely at the boundary between what is commonly thought of as low-level representation of signal and what is considered high-level representation of visual concepts. While some view computer vision as "applied mathematics" or "applied machine learning" or "image processing in disguise", I passionately believe the following:
I am not promulgating the thesis that all aspects of machine intelligence are visual, but I want to assure you that there are enough high-level semantic capabilities which must be set in place for vision to work, that it is not worthwhile to think of vision as smaller problem than general purpose intelligence. I believe that once we have made progress on vision (not in the narrow-universe setting) to the point where generic visual scene understanding is effectively solved, there won't be much left that needs to go into the "ethereal" mind which cognitive scientists want to empower machines with! The only way to make machines truly understand scenes, objects, and their interactions is to make machines know something about the fabric of human life, and it is important for machines to learn this for themselves from real-world experience. This goes beyond representing object appearance because folk physics, folk psychology, causality, spatio-temporal continuity, etc are all faculties which vision systems will need (at least the vision systems I want to ultimately build) for general purpose scene understanding. I don't want to undermine the efforts of cognitive scientists (which work on many of the theories/ideas I've delineated before), but perhaps only to convince them that I have been a cognitive scientist all along. I don't think placing a label on myself, by calling myself as either a cognitive scientist, a computer vision researcher, or AI researcher is very conducive to good research.

Cognitive Science is a computational study of the mind: McGill Cognitive Science
One of the biggest accomplishments in the field of Artificial Intelligence was when Deep Blue, a chess playing program developed at IBM, beat the world chess champion, Garry Kasparov. But this was in the early days of artificial intelligence -- when computer scientists still weren't sure on what it means for a machine to be intelligent. Chess is a well-known thinking-man's game, and at first glance it seems that a machine can only be worthy of being dubbed intelligent if it performs competitively on intelligent-people activities such as chess.
Chess: Human vs. Machine: Slate article about Deep Blue
Given the plethora of tasks that humans can effortlessly perform in daily life, is engineering a machine to rival humans on just one such task bringing researchers any closer to building truly intelligent machines?
The problem with chess is that it has a "finite universe problem" -- there is a finite number of primitives (the chess pieces) which can be manipulated by choosing a move from a finite set of allowable actions. But if we think of normal life (going to work, eating dinner, talking to a friend) as a game, then it is not hard to see that most everyday situations involving humans involve a sea of infinite objects (just look around and name all the different objects you can see around you!) and an equally capacious space of allowable actions (consider all the things you could with all those objects around you!). Intelligence is what allows us to cope with the complexities of the universe by focusing our attention on a limited set of relevant variables -- but the working set of objects/concepts we must consider at any single instant is chosen from a seemingly infinite set of alternatives.
I believe that everyday human-level visual intelligence is greatly undervalued by people -- and there is a very good reason for this! The ability to make sense of what is going on in a single picture is such a trivial and autonomous task for humans, that we don't even bother quantifying just how good we are at it. But let me reassure you that automated image understanding is no trivial feat. The world is not composed of 20 visual object categories and the space of allowable and interpretable utterances we could associate with a static picture is seemingly infinite. While the 20 category object detection task (as popularized by the PASCAL VOC) does have a finite universe problem, the grander version of the vision master problem (a combination of detection/recognition/categorization where you can interpret an input any way you like) is much more complex and mirrors the structure of the external world well.

Robotics Challenge: Build a Robot like Bender
Any application which calls for automated analysis of images requires vision. A robot, if it is to be successful interacting with the world and performing useful tasks, needs to perceive the external world and organize it. While some see vision as just one small piece of the "Robotics Challenge" (build a robot and make it do cool stuff), it totally unclear to me where to draw the boundary between low-level pixel analysis and high-level cognitive scene understanding. Over the years, I have been thinking more and more about this problem, and I've convinced myself that the interesting part of vision is precisely at the boundary between what is commonly thought of as low-level representation of signal and what is considered high-level representation of visual concepts. While some view computer vision as "applied mathematics" or "applied machine learning" or "image processing in disguise", I passionately believe the following:
Computer Vision is Artificial Intelligence
Wednesday, March 23, 2011
Kristen Grauman's CVPR 2011 papers
This year there are lots of new papers from Kristen Grauman's Computer Vision Group at UT-Austin, to be presented at CVPR 2011. There are lots of them, but not abstracts/PDFS yet. Here is a melange of pictures to entice us..







On another note, Antonio Torralba has a CVPR 2011 paper with Ruslan Salakhutdinov (Hinton's ex-PhD student) and Josh Tenenbaum, but I'll post info and pics after I get to read the paper.
Learning to Share Visual Appearance for Multiclass Object Detection
Ruslan Salakhutdinov, Antonio Torralba , and Josh Tenenbaum.
Learning the Easy Things First: Self-Paced Visual Category Discovery. Y. J. Lee and K. Grauman. To appear,Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, June 2011. [project page]

Boundary-Preserving Dense Local Regions. J. Kim and K. Grauman. To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, June 2011. (Oral)
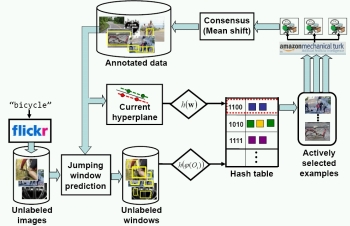
Large-Scale Live Active Learning: Training Object Detectors with Crawled Data and Crowds. S. Vijayanarasimhan and K. Grauman. To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, June 2011. (Oral)
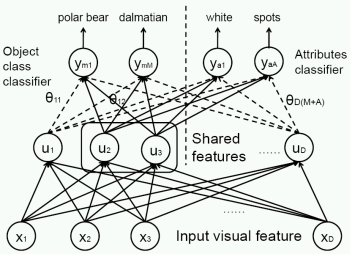
haring Features Between Objects and Their Attributes. S. J. Hwang, F. Sha, and K. Grauman. To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, June 2011.
Clues from the Beaten Path: Location Estimation with Bursty Sequences of Tourist Photos. C.-Y. Chen and K. Grauman. To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, June 2011. [project page]

Efficient Region Search for Object Detection. S. Vijayanarasimhan and K. Grauman. To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, June 2011.

Interactively Building a Discriminative Vocabulary of Nameable Attributes. D. Parikh and K. Grauman. To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, June 2011.
On another note, Antonio Torralba has a CVPR 2011 paper with Ruslan Salakhutdinov (Hinton's ex-PhD student) and Josh Tenenbaum, but I'll post info and pics after I get to read the paper.
Learning to Share Visual Appearance for Multiclass Object Detection
Ruslan Salakhutdinov, Antonio Torralba , and Josh Tenenbaum.
vision@github
Version control is a must if you're serious about software development. Like it or not, you have to be serious about software development if you want to build a large computer vision system (and perhaps get a PhD while doing it). Over the years, I've moved from CVS to SVN to git. I refuse to code without version control.
While git lets me easily share my private research code with my colleagues at CMU (much easier than svn), github lets me 'publish' it online in style. This is not the kind of sharing that most researchers do -- most researchers I know just put a tarball online. I've started playing around with github, and I'm really excited about using it for my own Computer Vision project.

I think sharing research code in a high-quality environment is necessary if we want to push the boundaries of machine intelligence in a team-like fashion. I think good papers and good code make good research, and while lots of care goes into high quality publications in the field, very few high-quality object recognition programs are published online "well". I think having forums, version control, wikis, etc is important if one wants a project to stand the test-of-time. I think github is the way to go if you're going to share your code online.
While git lets me easily share my private research code with my colleagues at CMU (much easier than svn), github lets me 'publish' it online in style. This is not the kind of sharing that most researchers do -- most researchers I know just put a tarball online. I've started playing around with github, and I'm really excited about using it for my own Computer Vision project.
I think sharing research code in a high-quality environment is necessary if we want to push the boundaries of machine intelligence in a team-like fashion. I think good papers and good code make good research, and while lots of care goes into high quality publications in the field, very few high-quality object recognition programs are published online "well". I think having forums, version control, wikis, etc is important if one wants a project to stand the test-of-time. I think github is the way to go if you're going to share your code online.
Tuesday, March 15, 2011

Subscribe to:
Posts (Atom)