On Thursday night, I saw "The Machine" -- a Pink Floyd Tribute band -- play in B.B. King's in New York City with my mom. Yes, with my mom; she's quite the avid Pink Floyd fan. Twas an excellent show; I got to hear every song from Animals, Money, Hey You, Time, Us and Them, Wish You Were Here, Shine On You Crazy Diamond, and many more.
Today it was raining in Patchogue, and I realized that I truly miss snow. I also miss Shadyside.
I've been working a lot lately and I will have some fun text segmentation results to show next week.
I hope everybody has a safe New Year's Eve tonight!!!
Saturday, December 31, 2005
Wednesday, December 21, 2005
on LI for the Holiday Season
Today was my first time driving to Patchogue, LI from Pittsburgh, PA. I only hit a little bit of GW Bridge traffic as the trip took 7.5 hours. I also found out that I got an A in Machine Learning. I still have to wait for my grade in Appearance Modeling (but it should be an A).
*Update* I did get my second A in Appearance Modeling.
Happy Holidays to everyone!
Here is a link to the Google Maps version of my Patchogue Jogging Path.
*Update* I did get my second A in Appearance Modeling.
Happy Holidays to everyone!
Here is a link to the Google Maps version of my Patchogue Jogging Path.
Snow action + Long Drive to LI
I went downhill skiing yesterday (first time in several years) at Seven Springs and it was really really fun! It was also my first time night skiing. I can't wait to go again; however, next time I might rent a snowboard.
In addition, here are some pics from last week's adventure in Western New York.

Here's a picture of my brother, Matt.

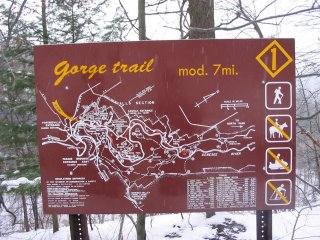
Here is a trail map for the park that we went hiking in.
I will be driving to Long Island of the Holiday Season in a few hours. I'll be missing the warmth and love of Shadyside.
In addition, here are some pics from last week's adventure in Western New York.

Here's a picture of my brother, Matt.

Here is a trail map for the park that we went hiking in.

I will be driving to Long Island of the Holiday Season in a few hours. I'll be missing the warmth and love of Shadyside.
Monday, December 19, 2005
"Once you make a decision, the universe conspires to make it happen."
"Once you make a decision, the universe conspires to make it happen."
-Ralph Waldo EmersonI just got back from the Union Grill with some first year Robograds. We had our Machine Learning final examination this morning, and it was soo much fun! I'm sure I did very well on the exam, because I'm very much into Machine Learning. However, once concept whose significance I failed to appreciate was PAC learning. What else is there to say: I am an anti PAC-learning kind of person.
I have a busy day ahead of me. First on the list is a visit to EMS for some snow gear. I should also mention that I've been recently playing more guitar (mastering overlapping modes) and have been very recently introduced to a band called Sonata Arctica.
Sunday, December 18, 2005
Geoff's Holiday Party Picture
Here is a picture from a pretty recent Holiday Party at Geoff's.

Me, Jenny (The girlfriend of a fellow Robotics PhD Student), and Mark (a fellow Robotics PhD Student) during Geoff's Holiday Party.

Me, Jenny (The girlfriend of a fellow Robotics PhD Student), and Mark (a fellow Robotics PhD Student) during Geoff's Holiday Party.

Friday, December 16, 2005
{Eigen,Dead,Snow}
Eigenvalues and eigenvectors put me in a very special place. I wish more would grok the beauty behind the vector space approach to mathematics.
Tonight I am going to see Dark Star Orchestra perform at Mr. Small's theatre. They are a Grateful Dead cover band and I've heard many great things about them. I'm wearing my tye-dye shirt right now and I'm quite excited. I walked to campus today while listening to YEM and whistling a Guyute. I'll be very glad if I get a {Cassidy,UJB,Dark Star,HOTW,Eyes,Scarlet Begonias} tonight.
I will post pictures about my snow-filled adventures with Matt, my brother, very soon. I also plan on going skiing on Tuesday, and I'm hella-excited. And if you're wondering, 'hella-excited' is indeed a techincal term denoting a 8.7/10.0 on the excitement/anticipation scale.
Tonight I am going to see Dark Star Orchestra perform at Mr. Small's theatre. They are a Grateful Dead cover band and I've heard many great things about them. I'm wearing my tye-dye shirt right now and I'm quite excited. I walked to campus today while listening to YEM and whistling a Guyute. I'll be very glad if I get a {Cassidy,UJB,Dark Star,HOTW,Eyes,Scarlet Begonias} tonight.
I will post pictures about my snow-filled adventures with Matt, my brother, very soon. I also plan on going skiing on Tuesday, and I'm hella-excited. And if you're wondering, 'hella-excited' is indeed a techincal term denoting a 8.7/10.0 on the excitement/anticipation scale.
The role of fiction: I am Michael Valentine Smith
Fiction plays a significant role in my everyday life. The reason why I prefer books over movies is that literature is more picturesque. Each image induced by a scenario depicted in a novel is painted with the internal brush, and I believe that such a mental exercise is healthy.
Generally the plot in a novel is somehow deeply related to the writer's own life, but one must realize that when I read a novel I'm not simply seeing the same mona-lisa that was painted by the author. In the same way that all observations are theory-laden, when I read novel X and you read novel X, we are seeing a somewhat different picture. There will always be certain concepts related to human life portrayed in the novel that make one reflect upon his/her own life experiences, and such an intimate connection with past experiences and the current immersion in the novel is not repeatable (with respect to other agents reading the novel).
It actually goes deeper than that. The world that each one of us lives in has been shaped by our life experiences. However, somebody will still ask me a question once in a while that is so deeply rooted in my own experiences that I cannot help but reply with a , "I don't know." In reality there's a good chance that I know the answer (know to myself). I simply choose not to attempt to project the answer from my own inner world onto their own little world. Sometimes concepts are lost in translation and until I feel that a particular concept will make the my-world to your-world leap unscathed, I will refrain from any such translations.
Don't think for one second that my musings into the world of literature are mini-journeys independent of the grand problem of object recognition. I'm simply trying to convey the point that there is something about past experience that is deeply related to current experience.
On another note, I'm currently reading Heinlen's Stranger in a Strange Land. I have become more like Michael Valentine Smith and he has become a little bit more like me.
Generally the plot in a novel is somehow deeply related to the writer's own life, but one must realize that when I read a novel I'm not simply seeing the same mona-lisa that was painted by the author. In the same way that all observations are theory-laden, when I read novel X and you read novel X, we are seeing a somewhat different picture. There will always be certain concepts related to human life portrayed in the novel that make one reflect upon his/her own life experiences, and such an intimate connection with past experiences and the current immersion in the novel is not repeatable (with respect to other agents reading the novel).
It actually goes deeper than that. The world that each one of us lives in has been shaped by our life experiences. However, somebody will still ask me a question once in a while that is so deeply rooted in my own experiences that I cannot help but reply with a , "I don't know." In reality there's a good chance that I know the answer (know to myself). I simply choose not to attempt to project the answer from my own inner world onto their own little world. Sometimes concepts are lost in translation and until I feel that a particular concept will make the my-world to your-world leap unscathed, I will refrain from any such translations.
Don't think for one second that my musings into the world of literature are mini-journeys independent of the grand problem of object recognition. I'm simply trying to convey the point that there is something about past experience that is deeply related to current experience.
On another note, I'm currently reading Heinlen's Stranger in a Strange Land. I have become more like Michael Valentine Smith and he has become a little bit more like me.
Wednesday, December 07, 2005
We spend a good portion of our lives asleep
I didn't get much sleep last night; however, waking up was remarkably easy this morning. I'll have plenty of time to catch up on sleep when I'm old. I think I'll try to keep my days long and my nights short. I might take a nap this afternoon, but it will surely be followed by an intense session at the gym and/or a run.
During the cold winter months we - mere mortals - spend lots of time thinking about warmth. Actually, it is more than just 'thinking' about warmth. Like the attraction between heavenly bodies, we gravitate towards warmth. Such an inverse squared relationship renders the force between us and a source of heat negligible when the distance is large; however, at close distances this force is unescapable. I shouldn't say unescapable, because I should stay true to my heavenly body analogy. This brutal quest for warmth implies a periodic relationship with our heat sources (consider the elliptical trajectories of the planets in our solar system). Periodicity is the driving element of life. Can you name an aspect of life that is not cyclical?
I think I'll take all the warmth I can get (and my apartment is pretty toasty most of the time) while gravitating towards a friendly source of fire. I don't believe that the universe will every dia a heat death, but I'd rather have a warm demise than a cold one.
On another note, I'm going to visit my brother this weekend up in Buffalo, NY. I saw a movie last night, and one character definitely reminded me of my bro. It was the CIA-father in Meet the Fockers.
Currently listening to: Fire
During the cold winter months we - mere mortals - spend lots of time thinking about warmth. Actually, it is more than just 'thinking' about warmth. Like the attraction between heavenly bodies, we gravitate towards warmth. Such an inverse squared relationship renders the force between us and a source of heat negligible when the distance is large; however, at close distances this force is unescapable. I shouldn't say unescapable, because I should stay true to my heavenly body analogy. This brutal quest for warmth implies a periodic relationship with our heat sources (consider the elliptical trajectories of the planets in our solar system). Periodicity is the driving element of life. Can you name an aspect of life that is not cyclical?
I think I'll take all the warmth I can get (and my apartment is pretty toasty most of the time) while gravitating towards a friendly source of fire. I don't believe that the universe will every dia a heat death, but I'd rather have a warm demise than a cold one.
On another note, I'm going to visit my brother this weekend up in Buffalo, NY. I saw a movie last night, and one character definitely reminded me of my bro. It was the CIA-father in Meet the Fockers.
Currently listening to: Fire
Tuesday, December 06, 2005
A Mitchell, a Moore, and an LDA Hacker
If you don't know what this title refers to, then I'll quickly remind you. Tom Mitchell and Andrew W. Moore are the two (high caliber) professors who are teaching the Machine Learning course I'm taking this semester.
First of all, I'd like to mention that Tom Mitchell is teaching a class titled "Advanced Statistical Language Processing" next semester.
The course description goes as follows:
This is an advanced, research-oriented course on statistical natural language processing. Students and the instructor will work together to understand, implement, and extend state-of-the-art machine learning algorithms for information extraction, named entity extraction, co-reference resolution, and related natural language processing tasks. The course will involve two primary activities: reading and discussing current research papers in this area, and developing a novel approach to continuous learning for natural language processing. More specifically, as a class we will work together to build a computer system that runs 24 hours/day, 7 days/week, performing two tasks: (1) extracting factual content from unstructured and semi-structured web pages, and (2) continuously learning to improve its competence at information extraction. We will begin the course with a simple prototype system of this type. During the course, students will populate it with a variety of statistical learning methods that enable it to extract information from the web, and to continuously learn to improve its capabilities.
Doesn't that sound awesome!
Secondly, Andrew Moore gave the last two lecture on reinforcement learning. What I like about this theory is that it literally places action in perception (remember Alva Noe's book titled "Action in Perception"). I think it is always exciting to see Andrew Moore talk about something he is passion about and these last two lectures were high quality.
Last, but not least, I got my Machine Learning project back today. 100/100. It was a great project and I feel like Jon and I deserved it. I'm generally much more proud of a high grade on a longer project compared to an exam and this is why I'm spreading my joy. I sent an email to Jon (since he is gone at NIPS [lucky, lucky, lucky] this week) and he said something like, "I went to a Jordan tutorial on hierarchical dirichlet processes." Then he summarized it all in 3 words: "It was intense." One day I will cross paths with this Michael Jordan fellow and I will be ready for the intensity that ensues.
First of all, I'd like to mention that Tom Mitchell is teaching a class titled "Advanced Statistical Language Processing" next semester.
The course description goes as follows:
This is an advanced, research-oriented course on statistical natural language processing. Students and the instructor will work together to understand, implement, and extend state-of-the-art machine learning algorithms for information extraction, named entity extraction, co-reference resolution, and related natural language processing tasks. The course will involve two primary activities: reading and discussing current research papers in this area, and developing a novel approach to continuous learning for natural language processing. More specifically, as a class we will work together to build a computer system that runs 24 hours/day, 7 days/week, performing two tasks: (1) extracting factual content from unstructured and semi-structured web pages, and (2) continuously learning to improve its competence at information extraction. We will begin the course with a simple prototype system of this type. During the course, students will populate it with a variety of statistical learning methods that enable it to extract information from the web, and to continuously learn to improve its capabilities.
Doesn't that sound awesome!
Secondly, Andrew Moore gave the last two lecture on reinforcement learning. What I like about this theory is that it literally places action in perception (remember Alva Noe's book titled "Action in Perception"). I think it is always exciting to see Andrew Moore talk about something he is passion about and these last two lectures were high quality.
Last, but not least, I got my Machine Learning project back today. 100/100. It was a great project and I feel like Jon and I deserved it. I'm generally much more proud of a high grade on a longer project compared to an exam and this is why I'm spreading my joy. I sent an email to Jon (since he is gone at NIPS [lucky, lucky, lucky] this week) and he said something like, "I went to a Jordan tutorial on hierarchical dirichlet processes." Then he summarized it all in 3 words: "It was intense." One day I will cross paths with this Michael Jordan fellow and I will be ready for the intensity that ensues.
Hey You
Hey you, out there in the cold
Getting lonely, getting old
Can you feel me?
Hey you, standing in the aisles
With itchy feet and fading smiles
Can you feel me?
Hey you, don’t help them to bury the light
Don’t give in without a fight.
Hey you, out there on your own
Sitting naked by the phone
Would you touch me?
Hey you, with you ear against the wall
Waiting for someone to call out
Would you touch me?
Hey you, would you help me to carry the stone?
Open your heart, I’m coming home.
Hey You - Pink Floyd
Getting lonely, getting old
Can you feel me?
Hey you, standing in the aisles
With itchy feet and fading smiles
Can you feel me?
Hey you, don’t help them to bury the light
Don’t give in without a fight.
Hey you, out there on your own
Sitting naked by the phone
Would you touch me?
Hey you, with you ear against the wall
Waiting for someone to call out
Would you touch me?
Hey you, would you help me to carry the stone?
Open your heart, I’m coming home.
Hey You - Pink Floyd
Saturday, December 03, 2005
FIRST LEGO League Robotics Challlenge Judging
I just returned from a fun-filled morning at NREC where I was a programming judge for the FIRST LEGO League Robotics Challenge. In this challenge, kids (9-14 years of age) had to build robots using LEGOs and program them using a graphical programming interface. My job was to talk to each team for 10 minutes while asking them questions and scoring them based on things such as {sophistication of approach, efficiency of approach, teamwork, planning the programming task, etc}.
It made me very happy to see young kids excited about science and technology. Playing with LEGOs is very hands-on approach to engineering and I saw kids from many different age groups show off their creativity. I was also particularly impressed by the large number of girl in the challenge and the fact that many of the most outstanding programs were developed by women.
I'm pretty sure that I want to do this again next year and I might even become a part of a longer educational program during the summer.
It made me very happy to see young kids excited about science and technology. Playing with LEGOs is very hands-on approach to engineering and I saw kids from many different age groups show off their creativity. I was also particularly impressed by the large number of girl in the challenge and the fact that many of the most outstanding programs were developed by women.
I'm pretty sure that I want to do this again next year and I might even become a part of a longer educational program during the summer.
Friday, December 02, 2005
Navigating two worlds
Today I want to talk about synonyms and photometric invariance while comparing and contrasting the world of language and the visual world. My primary objective is to build a vision system that can learn to recognize objects in an unsupervised or semi-supervised fashion. I want to stress the fact that I'm much more interested in machine learning these days than I ever was.
I have been recently introduced to unsupervised techniques in the field of statistical language modeling and the following discussion will revolve around the differences between the man-made world of text and the natural world of images.
Here, when I mention text I am referring to a legitimate configuration of English words. It is important to realize that in the world of language, there are two very different uses for words. In one case, words are mere vessels for the transportation of a high-level concept. Here, there is nothing special about a particular choice of words and many different configurations of words map to the same high-level semantic interpretation. On the other hand, a poetic use of language strives to convey a high-level meaning with a carefully selected configuration of words.
In the visual domain we can also treat images as having many purposes. In the first case images could capture 'a' configuration of the world and in the second case they could capture 'the' configuration of the world. Allow me to explain. 'A' configuration of the world represents a possible configuration of objects where there is nothing particularly interesting about that specific configuration. For example, when depicting 'a' configuration of a hikers camping on a mountaintop the color of the tent doesn't alter the high-level fact that there is a tent and the presence of snow on the mountain doesn't alter the mountain. On the other hand, when using images to capture 'the' configuration of the world the color of the tent and the presence of the snow does matter. 'The' configuration would represent some high-level concept such as 'Julie and Tim camping on Mount Sefton in March.' In the 'a' and 'the' configurations nothing was stated about the sky (cloudy, sunny, sunset,sunrise) thus both images could contain different skies while being true to their 'a' or 'the' purposes.
Although understanding the world of english text is easier than understanding the visual world, there are many similarities. Statistical co-occurence is the key idea behind unsupervised topic discovery and parts-of-speech tagging while it is also a necessary notion when trying to understand images. When local structures (letters,words,image patches) co-occur, we can use induction to explain this phenomenon. In some sense understanding data is not much more than mere compression of the data. Here I don't refer to compression as a way of reducing data set size so that the initial data set can be reconstructed in some L2-norm sense. I'm referring to a compression (a projection onto a lower dimensional space) such that the reconstruction preserves the high-level {semantic,visual} attributes that are relevant. Consider the 'the' configuration of the hikers mentioned in the paragraph above. A good compression would preserve {the identities of the hikers, the presence of snow, the colour of the tent} but it would discard anything about the sky if it was not relevant.
Within a few days I'll be posting my LDA results on unsupervised topic discovery in text. I will then quickly delineate some of the new directions I've been taking with respect to unsupervised segmentation of text (which was superficially concatenated as to eliminate the spaces) and how these results can be applied to the visual domain where object boundaries are what we want to find.
I have been recently introduced to unsupervised techniques in the field of statistical language modeling and the following discussion will revolve around the differences between the man-made world of text and the natural world of images.
Here, when I mention text I am referring to a legitimate configuration of English words. It is important to realize that in the world of language, there are two very different uses for words. In one case, words are mere vessels for the transportation of a high-level concept. Here, there is nothing special about a particular choice of words and many different configurations of words map to the same high-level semantic interpretation. On the other hand, a poetic use of language strives to convey a high-level meaning with a carefully selected configuration of words.
In the visual domain we can also treat images as having many purposes. In the first case images could capture 'a' configuration of the world and in the second case they could capture 'the' configuration of the world. Allow me to explain. 'A' configuration of the world represents a possible configuration of objects where there is nothing particularly interesting about that specific configuration. For example, when depicting 'a' configuration of a hikers camping on a mountaintop the color of the tent doesn't alter the high-level fact that there is a tent and the presence of snow on the mountain doesn't alter the mountain. On the other hand, when using images to capture 'the' configuration of the world the color of the tent and the presence of the snow does matter. 'The' configuration would represent some high-level concept such as 'Julie and Tim camping on Mount Sefton in March.' In the 'a' and 'the' configurations nothing was stated about the sky (cloudy, sunny, sunset,sunrise) thus both images could contain different skies while being true to their 'a' or 'the' purposes.
Although understanding the world of english text is easier than understanding the visual world, there are many similarities. Statistical co-occurence is the key idea behind unsupervised topic discovery and parts-of-speech tagging while it is also a necessary notion when trying to understand images. When local structures (letters,words,image patches) co-occur, we can use induction to explain this phenomenon. In some sense understanding data is not much more than mere compression of the data. Here I don't refer to compression as a way of reducing data set size so that the initial data set can be reconstructed in some L2-norm sense. I'm referring to a compression (a projection onto a lower dimensional space) such that the reconstruction preserves the high-level {semantic,visual} attributes that are relevant. Consider the 'the' configuration of the hikers mentioned in the paragraph above. A good compression would preserve {the identities of the hikers, the presence of snow, the colour of the tent} but it would discard anything about the sky if it was not relevant.
Within a few days I'll be posting my LDA results on unsupervised topic discovery in text. I will then quickly delineate some of the new directions I've been taking with respect to unsupervised segmentation of text (which was superficially concatenated as to eliminate the spaces) and how these results can be applied to the visual domain where object boundaries are what we want to find.
Wednesday, November 30, 2005
A treatise on 'Why Blog?' and Python Fun
Since I started monitoring the IPs of the people who visit my blog (via statcounter's free service), I've had 452 recorded unique hits. I quickly started thinking about the purpose of a blog and here are some insightful remarks (feel free to comment if you agree/disagree with any of these views):
The Diary-Blog
A blog can be be used to keep track of one's daily life. One can reconstruct significant events in their own life from reading their old blog entries. This is the 'my blog is for me' view. The only reason why this portrayal isn't perfectly aligned with the traditional notion of diary is that a blog is inherently public. Anybody can read anybody else's blog. The next few categories revolve around this very important depiction of a blog as a non-private collection of entries.
The News-About-Me-Blog
Since a blog is public and can be read by anybody with an internet connection, it is a way for the world to obtain information about the blogger without direct communication. In this view, the blog is the interface between the blogger and the rest of the world. A {stranger,friend,foe} doesn't have to bother the blogger by calling them to find out what they are up to and they don't even have to check their IM away message in the middle of the night. The Blog is always up since it is posted on the internet. However, in this view the outside world which reads the blog is nameless; it is a faceless corpus of readers.
The Philosophy-Blog (where comments are key)
By keeping the blog interesting the blogger can keep customers coming back. Here I use the word customer to denote a blog reader. Generally the satisfied customers are people who are interested in some of the topics that are conveyed throughout the blog. This allows the blogger to gear certain blog entries for that particular crowd. For example, throughout my blog a recurring theme is the philosophical questions "What is the world made of?" and how it relates to my current life as a researcher in the fields of computational vision and learning. By entertaining the customers who are also related in such deeper questions and interacting with them via comments, a blog can help exchange ideas with such a broad audience.
The I-am-talking-to-You-Blog
With tools such as Statcounter, a blogger who is competent in statistics can make many insightful inferences about the blog-viewing habits of his/her customers. Now, allow me (the blogger) to present you (the customer) with a rather intriguing use of the Blog. While the Philosophy-Blog was geared toward a large audience of people who share similar interests, the I-am-talking-to-you-Blog portrayal is centered around the key observation that one particular person will read the blog entry with an exceptionally high probability. Under this model, a particular blog entry is geared for one person, and one person only. However, due to the non-private nature of a blog, it is usually not obvious whether a blog entry was written for one person and whom that target person migh be. Surely the blogger could explicitly state who the blog entry was for and why, but that would defeat the whole purpose of person-targeting on a public blog! If a blogger wanted to say something directly, then they would use {phone,email,IM} as opposed to posting something on their blog! The genious behind the I-am-talking-to-you-Blog paradigm is that one can gear a blog entry for a particular customer and never state so directly; therefore, the blogger can always deny that the blog entry was geared towards any particular person! Clearly, a customer can only infer the true intentions/target of a blog entry when the blogger uses sophisticated obfuscatory techniques. By discussing content that is general enough for a broad audience to classify as random-talk yet specific enough that the target customer can transcend the seemingly random arrangement of words, the blogger can steer his voice in the proper direction.
In conclusion, I have written some Python code that automatically downloads people's blogs (their entire archive actually) in an attempt to mine the internet. The internet and well-formatted blogging is an ideal interface between people's most intimate thoughts and machines.
The Diary-Blog
A blog can be be used to keep track of one's daily life. One can reconstruct significant events in their own life from reading their old blog entries. This is the 'my blog is for me' view. The only reason why this portrayal isn't perfectly aligned with the traditional notion of diary is that a blog is inherently public. Anybody can read anybody else's blog. The next few categories revolve around this very important depiction of a blog as a non-private collection of entries.
The News-About-Me-Blog
Since a blog is public and can be read by anybody with an internet connection, it is a way for the world to obtain information about the blogger without direct communication. In this view, the blog is the interface between the blogger and the rest of the world. A {stranger,friend,foe} doesn't have to bother the blogger by calling them to find out what they are up to and they don't even have to check their IM away message in the middle of the night. The Blog is always up since it is posted on the internet. However, in this view the outside world which reads the blog is nameless; it is a faceless corpus of readers.
The Philosophy-Blog (where comments are key)
By keeping the blog interesting the blogger can keep customers coming back. Here I use the word customer to denote a blog reader. Generally the satisfied customers are people who are interested in some of the topics that are conveyed throughout the blog. This allows the blogger to gear certain blog entries for that particular crowd. For example, throughout my blog a recurring theme is the philosophical questions "What is the world made of?" and how it relates to my current life as a researcher in the fields of computational vision and learning. By entertaining the customers who are also related in such deeper questions and interacting with them via comments, a blog can help exchange ideas with such a broad audience.
The I-am-talking-to-You-Blog
With tools such as Statcounter, a blogger who is competent in statistics can make many insightful inferences about the blog-viewing habits of his/her customers. Now, allow me (the blogger) to present you (the customer) with a rather intriguing use of the Blog. While the Philosophy-Blog was geared toward a large audience of people who share similar interests, the I-am-talking-to-you-Blog portrayal is centered around the key observation that one particular person will read the blog entry with an exceptionally high probability. Under this model, a particular blog entry is geared for one person, and one person only. However, due to the non-private nature of a blog, it is usually not obvious whether a blog entry was written for one person and whom that target person migh be. Surely the blogger could explicitly state who the blog entry was for and why, but that would defeat the whole purpose of person-targeting on a public blog! If a blogger wanted to say something directly, then they would use {phone,email,IM} as opposed to posting something on their blog! The genious behind the I-am-talking-to-you-Blog paradigm is that one can gear a blog entry for a particular customer and never state so directly; therefore, the blogger can always deny that the blog entry was geared towards any particular person! Clearly, a customer can only infer the true intentions/target of a blog entry when the blogger uses sophisticated obfuscatory techniques. By discussing content that is general enough for a broad audience to classify as random-talk yet specific enough that the target customer can transcend the seemingly random arrangement of words, the blogger can steer his voice in the proper direction.
In conclusion, I have written some Python code that automatically downloads people's blogs (their entire archive actually) in an attempt to mine the internet. The internet and well-formatted blogging is an ideal interface between people's most intimate thoughts and machines.
Monday, November 28, 2005
Latent Topics and the Turing Test
Researchers in statistical language modeling employ the concept of a stoplist. A stoplist is a list of commonly occuring words such as "the", "of", and "are." When using a statistical technique based on the bag-of-words assumption (word exchangeability), these stopwords are discarded with the hope that the remaining words are the truly informative ones. Although suitable for classification and clustering tasks, such an approach falls short of modelling the syntax in the english language.
I believe that we should stop using stop lists. These 'meaningless' words are the glue that binds together informative words and if we want to be able to perform tasks such as grammar checking spelling checking then we have to look beyond bag-of-words. By complementing models such as LDA with a latent syntactic labels per word, we can attain partial exchangeability.
Latent Semantic Topc = A topic that is used to denote high-level information about the target sentence.
Latent Syntactic Topic = A topic which denotes the type of word (such as noun,verb,adjective).
Consider the sentence:
I read thick books.
This sentence is generated from the syntactic skeleton [noun,verb,adjective,noun].
Ideally we want a to understand text in such a way that the generative process generates text that appears to be generated by a human.
-----------------------------------
I would like to thank Jon for pointing out the Integrating Topics and Syntax paper which talks about this. Only two days after I posted this entry he showed me this paper (of course Blei is one of the authors).
I believe that we should stop using stop lists. These 'meaningless' words are the glue that binds together informative words and if we want to be able to perform tasks such as grammar checking spelling checking then we have to look beyond bag-of-words. By complementing models such as LDA with a latent syntactic labels per word, we can attain partial exchangeability.
Latent Semantic Topc = A topic that is used to denote high-level information about the target sentence.
Latent Syntactic Topic = A topic which denotes the type of word (such as noun,verb,adjective).
Consider the sentence:
I read thick books.
This sentence is generated from the syntactic skeleton [noun,verb,adjective,noun].
Ideally we want a to understand text in such a way that the generative process generates text that appears to be generated by a human.
-----------------------------------
I would like to thank Jon for pointing out the Integrating Topics and Syntax paper which talks about this. Only two days after I posted this entry he showed me this paper (of course Blei is one of the authors).
Tuesday, November 22, 2005
pittsburgh airport wireless
I'm currently sitting at the Pittsburgh Airport Terminal browsing the web. I finished reading Cryptonomicon 3 minutes ago.
I finished my Machine Project on Latent Dirichlet Allocation yesterday. I also won (tied for 1st actually) a photography competition in my Appearance Modeling class. Congrats Jean-Francois for splitting the win with me! Coincidently, we are working together on a project for that class.
Today in my Machine Learning class, Prof Mitchell talked about dimensionality reduction techniques. It still feels a bit weird when people call PCA and SVD an "unsupervised dimensionality reduction" technique. People should really make sure that they understand the singular value decomposition, not only as "some recondite matrix factorization", but as "the linear operator factorization."
I was thinking about using applying SVD to Latent Dirichlet Allocation features (the output of my machine lerning project). As an unsupervised machine learning technique, LDA automatically learns hidden topics. The output of LDA is the probability of a word belonging to a particular topics P(w|z). Variational inference could be used to find information about an unseed document. Given this novel document, we can determine P(z|d). In other words, LDA maps a document of arbitrary length to a vector on the K-simplex (the K-topic mixture proportions are a multinomial random variable).
By constructing a large data matrix with each row being the multinomial mixture weights of a particular document (this matrix woudl have as many columns as topics) and performing SVD, we would hope to be able to create a new set of K' uncorrelated topics. This is just like diagonalizing a matrix.
It would also be interesting to run LDA with a different number of topics (L={30,40,50,60,...,300}) and deterime the rank (or just look at the spectrum) of the data matrix. The rank would tell us how many 'truly independent' categories are present in our corpus. Here a category would be defined as a linear combination of latent topics, and it would be interesting to see how these 'orthonormal' categories obtained from SVD would relate to the original newsgroup categories.
I finished my Machine Project on Latent Dirichlet Allocation yesterday. I also won (tied for 1st actually) a photography competition in my Appearance Modeling class. Congrats Jean-Francois for splitting the win with me! Coincidently, we are working together on a project for that class.
Today in my Machine Learning class, Prof Mitchell talked about dimensionality reduction techniques. It still feels a bit weird when people call PCA and SVD an "unsupervised dimensionality reduction" technique. People should really make sure that they understand the singular value decomposition, not only as "some recondite matrix factorization", but as "the linear operator factorization."
I was thinking about using applying SVD to Latent Dirichlet Allocation features (the output of my machine lerning project). As an unsupervised machine learning technique, LDA automatically learns hidden topics. The output of LDA is the probability of a word belonging to a particular topics P(w|z). Variational inference could be used to find information about an unseed document. Given this novel document, we can determine P(z|d). In other words, LDA maps a document of arbitrary length to a vector on the K-simplex (the K-topic mixture proportions are a multinomial random variable).
By constructing a large data matrix with each row being the multinomial mixture weights of a particular document (this matrix woudl have as many columns as topics) and performing SVD, we would hope to be able to create a new set of K' uncorrelated topics. This is just like diagonalizing a matrix.
It would also be interesting to run LDA with a different number of topics (L={30,40,50,60,...,300}) and deterime the rank (or just look at the spectrum) of the data matrix. The rank would tell us how many 'truly independent' categories are present in our corpus. Here a category would be defined as a linear combination of latent topics, and it would be interesting to see how these 'orthonormal' categories obtained from SVD would relate to the original newsgroup categories.
Sunday, November 20, 2005
Root Reps in Cryptonomicon
While reading Neal Stephenson's Cryptonomicon I came across an interesting exchange between Enoch Root and Randy Waterhouse about Root Reps. A Root Rep (short for Root Representation) is an internal representation of Enoch Root, a mystical character in the novel. As stated in the book, the Root Rep is "some pattern of neurological activity," while the physical Enoch Root is some "big slug of carbon and oxygen and some other stuff." This concept was introduced by Enoch Root to reinforce the idea that the Root Rep is "the thing that you'll carry around in your brain for the rest of your life." Enoch Root said to Randy that instead of "thinking about me qua this big slug of carbon, you are thinking about the Root Rep."
I think that people should be aware how their actions influence their Reps (representations of themselves for other people). In this case a person's Rep is the neurological activity that is induced in another human's brain. We (made up of matter) can never truly enter another's person direct consciousness in a way that transcends the Rep. Although each one of us has a self-Rep that might be difficult to alter, each time we spread our Rep (by allowing others to communicate with us, read about us, or think about us in any way) we can influence the Rep creation.
What do you want to be today? Perhaps you cannot alter your own self-Rep very easily, but you can easily alter the Rep that is created inside other minds. Essentialy the Reps that represents us which is located inside other minds is based on a finite set of observations and thoughts that were most often a result of direct interactions. By carefully controling our interactions with others we can help shape the Rep. Cultivate a Rep today, be anything you want tomorrow.
I think that people should be aware how their actions influence their Reps (representations of themselves for other people). In this case a person's Rep is the neurological activity that is induced in another human's brain. We (made up of matter) can never truly enter another's person direct consciousness in a way that transcends the Rep. Although each one of us has a self-Rep that might be difficult to alter, each time we spread our Rep (by allowing others to communicate with us, read about us, or think about us in any way) we can influence the Rep creation.
What do you want to be today? Perhaps you cannot alter your own self-Rep very easily, but you can easily alter the Rep that is created inside other minds. Essentialy the Reps that represents us which is located inside other minds is based on a finite set of observations and thoughts that were most often a result of direct interactions. By carefully controling our interactions with others we can help shape the Rep. Cultivate a Rep today, be anything you want tomorrow.
Friday, November 18, 2005
Cartesian Philosophy, Computational Idealism, and a Machine-in-a-vat
Once my ideals congeal beyond the state of utter ineffability, I will upload an interesting short essay on Cartesian Philosophy to my blog. I will attempt to expose contemporary research in artificial intelligence as overly Cartesian. Additionaly, I will try to explain how postmodern philosophy based on social constructivism is necessary to advance the field of computational intelligence. Relating my ideas to the Cartesian concept of a "brain in a vat," I will also paint a Matrix-like picture where the key player in the machine intelligence game is the internet.
Wednesday, November 16, 2005
shackles of vocabulary
At first glance, the myriad of interchangeable terms found in the English language appears to enhance its expressive power. On the contrary, the freedom that one has in choosing the precise words to express his/her ideas can sometimes hinder communication. Not only can one uncompress a sentence into its primary intended meaning, but one can also extract additional secondary information from the mere choice of words. This additional channel of information could be used for stealth communication between two parties; however, it is most often used for a slightly different purpose. By entering the world of metaphor and dabbling in the field of primary meaning invariance, one can encode a sentence with a hierarchy of secondary meanings. While also useful for surreptitious exchange of information, the plurality of meaning provides the author with a mechanism for saying things that they don't want to say directly.
But you might ask yourself: why encode nonlinear meaning into a message as opposed to keeping it straightworward? Isn't there a possibility that the receiving party will fail to receive the hierarchy of secondary meanings? Sure, if we aren't trying to hide anything from an intermediate party then this hierarchical injection of information does nothing but obfuscate the primary message. But some of us still do it on a daily basis. I'd like to know why. It's not like we're trying to be poetic here.
But you might ask yourself: why encode nonlinear meaning into a message as opposed to keeping it straightworward? Isn't there a possibility that the receiving party will fail to receive the hierarchy of secondary meanings? Sure, if we aren't trying to hide anything from an intermediate party then this hierarchical injection of information does nothing but obfuscate the primary message. But some of us still do it on a daily basis. I'd like to know why. It's not like we're trying to be poetic here.
Saturday, November 12, 2005
softcore study of consciousness is for wimps
What is softcore study of consciousness? My personal view is that softcore study of anything is study performed by people who lack hardcore quantitative skills. For example, consider the contemporary philosopher who conveys his ideas by writing large corpora of text as opposed to any type of analysis (whether it be an empirical study or dabbling in gedanken-hilbert space).
If somebody wants to convince me that I should read their long publications on consciousness, they better be a hardcore scientist and not some type of calculus-avoiding softee.
Allow me to now boast of MIT's Center for Biological & Computational Learning. It's not like I one day decided to learn about biological research; I know of Tomaso Poggio (the big name associated with this lab) because a few weeks a go I wanted to learn about Reproducing Kernel Hilbert Spaces. Awesome! These guys are no dabblers and I personally encourage them to speak of consciousness. If you take a look at their publications list you'll notice that it is well aligned with my current academic interests. Their entire research plan supports the lemma that computer vision isn't all about machines!
If somebody wants to convince me that I should read their long publications on consciousness, they better be a hardcore scientist and not some type of calculus-avoiding softee.
Allow me to now boast of MIT's Center for Biological & Computational Learning. It's not like I one day decided to learn about biological research; I know of Tomaso Poggio (the big name associated with this lab) because a few weeks a go I wanted to learn about Reproducing Kernel Hilbert Spaces. Awesome! These guys are no dabblers and I personally encourage them to speak of consciousness. If you take a look at their publications list you'll notice that it is well aligned with my current academic interests. Their entire research plan supports the lemma that computer vision isn't all about machines!
Wednesday, November 09, 2005
Broader Impacts Season Ends
Broader Impacts season has just ended. Final Standings reported below:
Tomasz: 12-4
Broader Impacts: 11-5
Intellectual Merit: 16-0
NSF: 4-12
Sleep: 6-10
I would like to thank Justin, Vince, Aiah, and most notably Alyosha for their insightful comments regarding my NSF essays. Now it's time to focus on unsupervised learning and probabilistic graphical models.
-Tomasz
Tomasz: 12-4
Broader Impacts: 11-5
Intellectual Merit: 16-0
NSF: 4-12
Sleep: 6-10
I would like to thank Justin, Vince, Aiah, and most notably Alyosha for their insightful comments regarding my NSF essays. Now it's time to focus on unsupervised learning and probabilistic graphical models.
-Tomasz
Tuesday, November 08, 2005
Action at a Distance and Computer Vision
The problem of action at a distance which was around since the time of Newton still plagues us. While introduced in the context of gravitational attraction between two heavenly bodies, it has recently came up again in the context of object independence. Allow me to quickly explain.
The original problem was: how can two objects instantaneously 'communicate' via a gravitational attraction? How can scientists make sense of this action at a distance?
In the context of vision, how does the localization of one object influence the localization of another object in a scene? In other words, how can information about object A's configuration be embedded in object B's configuration?
Being the postmodern idealist that I am, I am not afraid to post the thesis that we, the perceivers, are the quark gluon plasma that binds together the seemingly distinct bits of information we acquire from the world. Perhaps what we semantically segment and label as object A is nothing but a subjective boundary that allows our perception to relate it to another subjective semantic segmentation called object B. When working on your next research project, remember that maybe the world isn't made up of things that you can see.
The original problem was: how can two objects instantaneously 'communicate' via a gravitational attraction? How can scientists make sense of this action at a distance?
In the context of vision, how does the localization of one object influence the localization of another object in a scene? In other words, how can information about object A's configuration be embedded in object B's configuration?
Being the postmodern idealist that I am, I am not afraid to post the thesis that we, the perceivers, are the quark gluon plasma that binds together the seemingly distinct bits of information we acquire from the world. Perhaps what we semantically segment and label as object A is nothing but a subjective boundary that allows our perception to relate it to another subjective semantic segmentation called object B. When working on your next research project, remember that maybe the world isn't made up of things that you can see.
Saturday, November 05, 2005
a bag of words and can of whoop ass
If you are interested in object recognition then you must check out the ICCV 2005 short course on Recognizing and Learning Object Categories.
From the link:
This course reviews current methods for object category recognition, dividing them into four main areas: bag of words models; parts and structure models; discriminative methods and combined recognition and segmentation. The emphasis will be on the important general concepts rather than in depth coverage of contemporary papers. The course is accompanied by extensive Matlab demos.
From the link:
This course reviews current methods for object category recognition, dividing them into four main areas: bag of words models; parts and structure models; discriminative methods and combined recognition and segmentation. The emphasis will be on the important general concepts rather than in depth coverage of contemporary papers. The course is accompanied by extensive Matlab demos.
Friday, November 04, 2005
vision people like eyes
My life as a graduate student consists of coming up with crazy ideas related to machine perception of the visual world. Somewhere between the cold objective yet uninterpretable reality and the resplendent human mind lies the human visual system. I'm not actually into retinas per se. However, I strive to understand the process that is responsible for understanding the visual world. Inadvertently, I am into gateways between the objective and the subjective (ie I'm into eyes in the metaphorical sense).
Many people would agree with the statement that the personal experience of 'thinking' is rather subjective, while the personal experience of 'seeing' is rather objective when two different people are looking at the same thing. However, I dont agree with this statement. I'm rather skeptical of a hard split between the objective world and the subjective realm inside us. If vision is observation and thinking is theory, then Popper's thesis that all observations are theory laden translates as follows: seeing is tainted with intelligence. I'm not saying that it is the eyes that are doing anything magical to transform the cold soulless material world to the warm and fuzzy subjective real of inner consciousness; however, visual information is processed via this gateway and if we want to ever reconstruct (or at least fit a naive model) someone's inner realm then we have to start hacking the eyes.
Perhaps we should not be looking for intelligence in people's brains. Perhaps we (I?) should look at the gateway between the objective and the subjective.
I like to wear sunglasses so that people don't know what I'm thinking. The gateway is the weakest link and I don't want to be exposed to crackers. Even though I'm not overly afraid of van eck phreakers peeking into my soul, I still wear shades. But you and I don't really need expensive van eck phreaking apparatus (fMRI?) when we have our own eyes. Peek into an eye today and learn an idea tomorrow.
Many people would agree with the statement that the personal experience of 'thinking' is rather subjective, while the personal experience of 'seeing' is rather objective when two different people are looking at the same thing. However, I dont agree with this statement. I'm rather skeptical of a hard split between the objective world and the subjective realm inside us. If vision is observation and thinking is theory, then Popper's thesis that all observations are theory laden translates as follows: seeing is tainted with intelligence. I'm not saying that it is the eyes that are doing anything magical to transform the cold soulless material world to the warm and fuzzy subjective real of inner consciousness; however, visual information is processed via this gateway and if we want to ever reconstruct (or at least fit a naive model) someone's inner realm then we have to start hacking the eyes.
Perhaps we should not be looking for intelligence in people's brains. Perhaps we (I?) should look at the gateway between the objective and the subjective.
I like to wear sunglasses so that people don't know what I'm thinking. The gateway is the weakest link and I don't want to be exposed to crackers. Even though I'm not overly afraid of van eck phreakers peeking into my soul, I still wear shades. But you and I don't really need expensive van eck phreaking apparatus (fMRI?) when we have our own eyes. Peek into an eye today and learn an idea tomorrow.
Tuesday, November 01, 2005
An analogy, Karl Popper, and science for machines
There is a nice analogy between the problem of segmentation and the problem of object detection/classification/recognition.
Segmentation is grouping on an intra-image spatial level.
Detection/classification/recognition is grouping on an inter-image level.
Tracking is grouping at the inter-frame temporal level.
--------------------
Let me remind the remind about the Theory Observation Distinction that is mainly attributed to Karl Popper. "All observation is selective and theory-laden," and similar quotes can be found on Stanford's Encyclopedia of Philosophy entry on Karl Popper. The entry further states that Popper repudiates induction and rejects the view that it is the characteristic method of scientific investigation and inference, and substitutes falsifiability in its place.
Researchers in the field of machine vision could learn from the philosophy of science. When placed in the context of machine intelligence, Popper's ideas sound like this:
The notion of training a system to classify images by presenting it with a large set of labeled examples and building an visual model is analogous to using induction over a finite set of observables. However, since a lesson on science has taught us that there is much to say about positing a theory, maybe we should be less concerned with machines that perform data-driven model building and more concerned with building machines that can posit models and verify them.
----------
Should we be building machines that posit scientific theories, or are we doing this already?
Segmentation is grouping on an intra-image spatial level.
Detection/classification/recognition is grouping on an inter-image level.
Tracking is grouping at the inter-frame temporal level.
--------------------
Let me remind the remind about the Theory Observation Distinction that is mainly attributed to Karl Popper. "All observation is selective and theory-laden," and similar quotes can be found on Stanford's Encyclopedia of Philosophy entry on Karl Popper. The entry further states that Popper repudiates induction and rejects the view that it is the characteristic method of scientific investigation and inference, and substitutes falsifiability in its place.
Researchers in the field of machine vision could learn from the philosophy of science. When placed in the context of machine intelligence, Popper's ideas sound like this:
The notion of training a system to classify images by presenting it with a large set of labeled examples and building an visual model is analogous to using induction over a finite set of observables. However, since a lesson on science has taught us that there is much to say about positing a theory, maybe we should be less concerned with machines that perform data-driven model building and more concerned with building machines that can posit models and verify them.
----------
Should we be building machines that posit scientific theories, or are we doing this already?
Sunday, October 30, 2005
80's night good vibe + The New Deal in NYC?
I attended 80's night at The Upstage in Oakland this past Thursday. It was a lot of fun!
Even though I had to miss my Thursday night lift, the dance floor gave my legs a good workout. Dancing is a lot of fun; it reminded me of how much I love The New Deal shows. By the way, The New Deal is playing in NYC this new years and I might go. Below is the info
BB Kings ++Late Night New Year's Eve THE NEW DEAL @ BB Kings
Doors 1am Show 1:30am
$25.50 advance $30.00 day of show
This is an All Ages Show
Even though I had to miss my Thursday night lift, the dance floor gave my legs a good workout. Dancing is a lot of fun; it reminded me of how much I love The New Deal shows. By the way, The New Deal is playing in NYC this new years and I might go. Below is the info
BB Kings ++Late Night New Year's Eve THE NEW DEAL @ BB Kings
Doors 1am Show 1:30am
$25.50 advance $30.00 day of show
This is an All Ages Show
Advance tix available through ticketmaster.com, ticketmaster phone: 212-307-7171, bb king box office located at BB King's 237 west 42nd street NYC - Box Office Hours - 11am to 11pm daily.
Monday, October 24, 2005
Semantic Segmentation, Omnipotency Problem, Ill-Posing, and Futility
Disclaimer: I found this text file on my computer and I am deciding to post it as is. I probably never finished writing it, and meant to edit things later. But we all know how these things go (meaning that it would have never been finished).
So here it is:
First, let us discuss the notion of an object detector, then think about how the problem of image understanding is generally posed and finally look at a simple gedanken experiment.
I. The life of an object detector
An object detector's role is to localize an object in an image. Generally a large training set is obtained which consists of manually labelled images. These images contain an instance (or several instances) of the object of interest and additionally the location of the object of interest is also known. The training set is usually large enough to capture view of the object of interest under different orientations, scales, and lighting conditions. The training set has to generally be much larger if we want to detect a member of an object class such as a car versus the recognition of a particular object such as my car. Object detection refers to finding a member of a class while object recognition refers to finding that particular instance.
Why object detection? Generally one is interested in a particular vision task such as creating an autonomous vehicle that can drive on highways. In this case, the vision researcher can reason about the types of objects that are generally seen in the particular application and train object detection modules for each object type. A car detector, a road sign detector, a tree detector, a bridge detector, a road lane detector, a person detector, a grass detector, a cloud detector, a gas station detector, a police car detector, and a sun detector could be used in combination to create a pretty decent scene understanding system. This system would look at at an image and segment it by assigning each pixel in the image as belonging to one of those classes or the 'unclassified' category. This 'unclassified category' is also known as the background category, or the clutter category; it represents the 'uninteresting' stuff.
II. What comes after seeing
Awesome! I just concocted a recipe for creating an autonomous vehicle!
Unfortunately, there are several problems with this approach. First of all, segmenting an image into the categories spelled out above falls short of having a car known what it should do to navigate this visual world. I didn't talk about the segmentation of a image captured by a camera on top of a vehicle relates to navigation. Apparently, this recipe is only good for asking queries of he type, 'Where is object O in the image I?' Unfortunately, the only thing that is really interesting is the question, 'What do I do once i see image I?'
III. Semantic Segmentation
The problem of computer vision is traditionally posed as something like this: Given an image I, segment it into semantic categories and give me the 3D position and orientation of the objects found in the image with respect to the camera center. In addition we could also want information about lighting in the scene so that we can recover the true appearance of the objects we found in the image. I want to call this mapping of image into a set of locations/orientations of objects, object labels, and lighting conditions a semantic segmentation.
It seems that if we could obtain this semantic segmentation, we could then learn a mapping from a semantic segmentation to an action in order to have a real vision system.
--Omnipotency problem of vision
The problem with this approach is what I will refer to as the omnipotency problem of vision. This problem is that a vision system is required to know everything about the visual world in order to know what action to take. I honestly don't believe that we need to all this information about the world to know what to do. A vision system should only care about extracting the minimal amount of information from an image in order to know what to do next within some small error threshold.
-- Scaling problems with unbounded growth of object categories
Another problem with this the semantic segmentation approach is that it doesn't scale when you start looking at vision systems that can perform a large number of vision tasks. The number of object categories is extremely large!
-- Ill-defined object categories
The big problem that I want to talk about is the problem of defining the objects that our system would detect. Do we have a separate object for 'baby' and 'old-man' or treat them as just large geometric deformation of the concept 'human'? When you take one tire off of a car, it is still a car; but when you start taking more and more pieces off of it when does it cease to be a 'car'? Should a tree be considered one object or should we treat it as an assembly of {leaves,branches,trunk}? Clearly the notion of 'object' is ill-defined. I think the biggest problem with contemporary vision is that not enough people really see how grand of a problem it is. Computer Vision isn't only concerned with hacking out a driving system; the deep questions that arise are some of the deepest philosophical questions that have been around since the start of man's inquiry.
--Naive desires
Will we ever solve the problem of computer vision? When somebody thinks of this problem in a naive 'hack-out-a-system' kind of way, then one would also think 'why not?' However, when one sees beyond the systems, beyond the geometry, and beyond the statistical modeling then one can see that the problem of computer vision isn't really about computers at all! How do we (humans) live so effortlessly in this complex world around us? This question has many nuances, and every generation of great thinkers has asked a slightly different question. Of course this makes perfect sense, since each generation has been thinking within the paradigm of their time and it is probably not a good idea to even think of this as a variation of the same question when we consider the incommensurability of ideas across paradigm shifts.
--The big problem: The bold answer
Will we ever solve the problem of computer vision? Of course not. If you (the reader) still think that you can solve this problem, then you need to get out more.
So here it is:
First, let us discuss the notion of an object detector, then think about how the problem of image understanding is generally posed and finally look at a simple gedanken experiment.
I. The life of an object detector
An object detector's role is to localize an object in an image. Generally a large training set is obtained which consists of manually labelled images. These images contain an instance (or several instances) of the object of interest and additionally the location of the object of interest is also known. The training set is usually large enough to capture view of the object of interest under different orientations, scales, and lighting conditions. The training set has to generally be much larger if we want to detect a member of an object class such as a car versus the recognition of a particular object such as my car. Object detection refers to finding a member of a class while object recognition refers to finding that particular instance.
Why object detection? Generally one is interested in a particular vision task such as creating an autonomous vehicle that can drive on highways. In this case, the vision researcher can reason about the types of objects that are generally seen in the particular application and train object detection modules for each object type. A car detector, a road sign detector, a tree detector, a bridge detector, a road lane detector, a person detector, a grass detector, a cloud detector, a gas station detector, a police car detector, and a sun detector could be used in combination to create a pretty decent scene understanding system. This system would look at at an image and segment it by assigning each pixel in the image as belonging to one of those classes or the 'unclassified' category. This 'unclassified category' is also known as the background category, or the clutter category; it represents the 'uninteresting' stuff.
II. What comes after seeing
Awesome! I just concocted a recipe for creating an autonomous vehicle!
Unfortunately, there are several problems with this approach. First of all, segmenting an image into the categories spelled out above falls short of having a car known what it should do to navigate this visual world. I didn't talk about the segmentation of a image captured by a camera on top of a vehicle relates to navigation. Apparently, this recipe is only good for asking queries of he type, 'Where is object O in the image I?' Unfortunately, the only thing that is really interesting is the question, 'What do I do once i see image I?'
III. Semantic Segmentation
The problem of computer vision is traditionally posed as something like this: Given an image I, segment it into semantic categories and give me the 3D position and orientation of the objects found in the image with respect to the camera center. In addition we could also want information about lighting in the scene so that we can recover the true appearance of the objects we found in the image. I want to call this mapping of image into a set of locations/orientations of objects, object labels, and lighting conditions a semantic segmentation.
It seems that if we could obtain this semantic segmentation, we could then learn a mapping from a semantic segmentation to an action in order to have a real vision system.
--Omnipotency problem of vision
The problem with this approach is what I will refer to as the omnipotency problem of vision. This problem is that a vision system is required to know everything about the visual world in order to know what action to take. I honestly don't believe that we need to all this information about the world to know what to do. A vision system should only care about extracting the minimal amount of information from an image in order to know what to do next within some small error threshold.
-- Scaling problems with unbounded growth of object categories
Another problem with this the semantic segmentation approach is that it doesn't scale when you start looking at vision systems that can perform a large number of vision tasks. The number of object categories is extremely large!
-- Ill-defined object categories
The big problem that I want to talk about is the problem of defining the objects that our system would detect. Do we have a separate object for 'baby' and 'old-man' or treat them as just large geometric deformation of the concept 'human'? When you take one tire off of a car, it is still a car; but when you start taking more and more pieces off of it when does it cease to be a 'car'? Should a tree be considered one object or should we treat it as an assembly of {leaves,branches,trunk}? Clearly the notion of 'object' is ill-defined. I think the biggest problem with contemporary vision is that not enough people really see how grand of a problem it is. Computer Vision isn't only concerned with hacking out a driving system; the deep questions that arise are some of the deepest philosophical questions that have been around since the start of man's inquiry.
--Naive desires
Will we ever solve the problem of computer vision? When somebody thinks of this problem in a naive 'hack-out-a-system' kind of way, then one would also think 'why not?' However, when one sees beyond the systems, beyond the geometry, and beyond the statistical modeling then one can see that the problem of computer vision isn't really about computers at all! How do we (humans) live so effortlessly in this complex world around us? This question has many nuances, and every generation of great thinkers has asked a slightly different question. Of course this makes perfect sense, since each generation has been thinking within the paradigm of their time and it is probably not a good idea to even think of this as a variation of the same question when we consider the incommensurability of ideas across paradigm shifts.
--The big problem: The bold answer
Will we ever solve the problem of computer vision? Of course not. If you (the reader) still think that you can solve this problem, then you need to get out more.
maybe the world isn't made up of objects
Disclaimer: I found this text file on my computer and I don't remember when I wrote this, but probably sometime in September.
The classic problem of computer vision is centered around the sub-problem of object recognition?
However, one key observation about vision is that work in this field has produced any stunning results in over 30 years of work. Perhaps people have been attacking this problem from the wrong direction.
When somebody is trying to do good object-recognition they would like to extract the locations of objects in an image. Recently, researchers have begun using machine learning techniques to learn the space of all object appearances; however, maybe the answer to this problem isn't in extracting objects from images.
When a human sees an image they see they can easily decompose the image into its constituent parts, namely the objects present in the scene. But is this statement really true about the nature of the human visual system? Language and society have introduced 'objects' into our understanding of the world, but perhaps we can still do vision without focusing on objects.
If we treat the image as a holistic entity, perhaps once we have seen enough images so that 'object' segmentation naturally happens. If a human was never given a language-based context for describing what they see, would they see objects?
Are objects an artifact of the fact that human experience is in most-part dominated by the language we know. Clearly language is concerned with objects.
We should perhaps focus on image understanding as a memory-based approach. Thus to understand a scene we might not really need to segment it into object categories. Perhaps we only need to associate a given scene with some other scene we have encountered.
The classic problem of computer vision is centered around the sub-problem of object recognition?
However, one key observation about vision is that work in this field has produced any stunning results in over 30 years of work. Perhaps people have been attacking this problem from the wrong direction.
When somebody is trying to do good object-recognition they would like to extract the locations of objects in an image. Recently, researchers have begun using machine learning techniques to learn the space of all object appearances; however, maybe the answer to this problem isn't in extracting objects from images.
When a human sees an image they see they can easily decompose the image into its constituent parts, namely the objects present in the scene. But is this statement really true about the nature of the human visual system? Language and society have introduced 'objects' into our understanding of the world, but perhaps we can still do vision without focusing on objects.
If we treat the image as a holistic entity, perhaps once we have seen enough images so that 'object' segmentation naturally happens. If a human was never given a language-based context for describing what they see, would they see objects?
Are objects an artifact of the fact that human experience is in most-part dominated by the language we know. Clearly language is concerned with objects.
We should perhaps focus on image understanding as a memory-based approach. Thus to understand a scene we might not really need to segment it into object categories. Perhaps we only need to associate a given scene with some other scene we have encountered.
Wednesday, October 19, 2005
Reproducing Kernels
I'm starting to get a handle on this RKHS business. In fact, I can't wait to learn about SVMs in my ML class!
Latent Dirichlet Allocation
I have begun work on a MATLAB implementation of Latent Dirichlet Allocation ala Blei(who is currently at CMU). Jon and I will be looking at classification/clustering/searching of a data set made up of 20,000 newsgroup articles.
LDA does not model a document as belonging to one topic. Instead, each document from the corpus is modeled as a finite mixture of topics. In this generative probabilistic model, parameter estimation and inference are the two main algorithms that we will implement.
I am interested in LDA for several reasons. Primarily I want experience implementing machine learning algorithms; however, LDA is actually of interest to vision researchers. I think this project will teach me useful things about Machine Learning and I look forward to having a MATLAB implementation of LDA that I can later adopt for vision tasks.
LDA does not model a document as belonging to one topic. Instead, each document from the corpus is modeled as a finite mixture of topics. In this generative probabilistic model, parameter estimation and inference are the two main algorithms that we will implement.
I am interested in LDA for several reasons. Primarily I want experience implementing machine learning algorithms; however, LDA is actually of interest to vision researchers. I think this project will teach me useful things about Machine Learning and I look forward to having a MATLAB implementation of LDA that I can later adopt for vision tasks.
Sunday, October 16, 2005
NSF application + Gamma Function Awesomeness
I already mailed in a transcript request for RPI to send out my undergraduate transcript to three fellowship agencies. I'm applying to NSF Graduate Research Fellowship Program, DoD National Defense Science and Engineering Graduate Fellowship, and DOE Computational Science Graduate Fellowship. I usually refer to them as NSF,NDSEG, and CSGF. I received Honorable Mention from NSF last year, so I think I have a decent chance of winning it this time around.
On another note, I've been summing up infintie series like there's no tomorrow. I've grown rather fond of the gamma function which allows me to deal with integrals of polynomials over the positive real line when they are weighted by the e^(-x). In fact, I have experimented with freely adding n!/n! terms into my infinite series and re-writing the numerator as a gamma integral. Then I would reverse summation and integration, rearrange, and play with the newly created beast.
I've also been reading up on RKHS From Poggio's course website. I have made a comprehensive list of machine learning links on my CMU webpage.
On another note, I've been summing up infintie series like there's no tomorrow. I've grown rather fond of the gamma function which allows me to deal with integrals of polynomials over the positive real line when they are weighted by the e^(-x). In fact, I have experimented with freely adding n!/n! terms into my infinite series and re-writing the numerator as a gamma integral. Then I would reverse summation and integration, rearrange, and play with the newly created beast.
I've also been reading up on RKHS From Poggio's course website. I have made a comprehensive list of machine learning links on my CMU webpage.
Friday, October 14, 2005
Machine Teaching instead of Machine Learning
Being a disciple of the Machine Learning paradigm, I am not-so-proud to state that what is called 'Machine Learning' these days is actually more like Machine Teaching. Being a student who has decided to dedicate most of his time to his academic endeavours, I can honestly that it is I who is 'Learning.' Each time I learn something new I program it into the little box next to me. Believe me, this box is not learning anything. Until I feed it training data it doesn't really have any motivation to do anything on its own.
The problem is that these classifers and clustering units are very dependent on humans giving them data. It take a lot of intelligence (on the part of the human) to make a decently smart (on the part of the machine) algorithm, but it is far from intelligent.
The problem is that these classifers and clustering units are very dependent on humans giving them data. It take a lot of intelligence (on the part of the human) to make a decently smart (on the part of the machine) algorithm, but it is far from intelligent.
Wednesday, October 12, 2005
Discovering Laguerre Polynomials and Shortcomings of Darwinian Evolution
I was recently playing with the Gamma Function, and realized how it could be used to help evaluate a certain type of weighted inner product between polynomials defined over [0,inf). After a few hours of playing, I finally googled this type of expansion and was non-surprised to find these polynomials called Laguerre Polynomials. These orthonormal polynomials could be used to define a Laguerre-Fourier expansion of functions with a wider support than the other orthonormal polynomials such as the Legendre polynomials.
I recently had a interesting conversation with my friend Mark about the 'missing link' in evolutionary theory. We both agreed that one problem with Darwinian Evolution is that it requires some special mechanism for humans to possess that would explain their superiority in the modern world. We pretty much agreed on the fact that an advanced theory of mating partner selection can be ruled out on the basis of empirical evidence. Although a theory of intelligent partner selection could explain man's dominance in the modern world, the empirical evidence shows that modern man's selection algorithm is rather arbitrary. It brings back the 'big' question, "Why are we so advanced?"
I recently had a interesting conversation with my friend Mark about the 'missing link' in evolutionary theory. We both agreed that one problem with Darwinian Evolution is that it requires some special mechanism for humans to possess that would explain their superiority in the modern world. We pretty much agreed on the fact that an advanced theory of mating partner selection can be ruled out on the basis of empirical evidence. Although a theory of intelligent partner selection could explain man's dominance in the modern world, the empirical evidence shows that modern man's selection algorithm is rather arbitrary. It brings back the 'big' question, "Why are we so advanced?"
Sunday, October 09, 2005
zeta strikes again!
I found my Riemann Zeta book Friday night. I say 'found' because after a few weeks of tripping on the Zeta, I try to 'hide' this book so that I forget about Zeta for a little bit.
Now I've been summing up series like crazy for a day or two. A recurring these in my own little math sessions is the hyperbolic(not in sense of 'hyperbola') use of infinite series and orthogonal function expansions.
Now I want Hardy's Divergent Series book!
Now I've been summing up series like crazy for a day or two. A recurring these in my own little math sessions is the hyperbolic(not in sense of 'hyperbola') use of infinite series and orthogonal function expansions.
Now I want Hardy's Divergent Series book!
Saturday, October 08, 2005
the problem of neural nets: the problem of people
The basic problem with artificial neural networks is very similar to the problem with people in the year 2005. A neural network is very sensitive to the order of training inputs it is presented. In fact, it is possible for a neural network to be presented training inputs in such an order that it forgets 'old input-output' pairs. This type of behavior is known as overfitting.
When did I start to overfit?
Sometime back in 10th grade of high school I was presented with a lot of input relating to my current scholastic endeavours. This overstimulation of the quantitative part of my brain has left me in a rather peculiar situation.
Why didn't anybody present me with a test set?
The problem of overstimulation of the quantitative part of the brain is that the distribution of analytic reasoning tasks is not representative of the distribution of tasks in the real-world. My schooling is analogous to the training of a neural network, where the purpose of the GPA is well aligned with the notion of a performance. However, as in the case of overfitting, the notion of a GPA fails to generalize to non-scholarly tasks and thus the performance of a pupil in a school systems falls short of predicting performance on common real-world tasks.
In the year 2005, many people overfit some aspect of life. I prefer to use the term 'overfit' as opposed to overspecialize because it draws upon the context of regression (fitting). When each person is treated independently of others, overfitting can only be seen as a bad thing. When does one person really want a neural network to overfit? However, in the context of society's machine, overfits are the ones who expand the horizon of modern life. It is as if overfitting was brought about by evolution. Evolution probably favored species who steadily produced a small, yet non-infinitesimal, percent of overfitters. Since people can be seen as the cream of the crop with respect to many evolutionary metrics, it is of no surprise that we are overfitting so well.
Overfitters unite!
I think people can learn about themselves by studying machine learning. In a good article titled "The Parallel Distributed Processing Approach to Semantic Cognition" by James L. McClelland and Timothy T. Rogers, degradation of semantic knowledge in humans (a condition known as sementic dementia) was compared to the behavior of a neural network. Traditionally scientists would study humans in an attempt to develop better computational techniques for tasks such as machine learning and machine vision, but it is important to study computational techniques because they can tell us something about ourselves.
When did I start to overfit?
Sometime back in 10th grade of high school I was presented with a lot of input relating to my current scholastic endeavours. This overstimulation of the quantitative part of my brain has left me in a rather peculiar situation.
Why didn't anybody present me with a test set?
The problem of overstimulation of the quantitative part of the brain is that the distribution of analytic reasoning tasks is not representative of the distribution of tasks in the real-world. My schooling is analogous to the training of a neural network, where the purpose of the GPA is well aligned with the notion of a performance. However, as in the case of overfitting, the notion of a GPA fails to generalize to non-scholarly tasks and thus the performance of a pupil in a school systems falls short of predicting performance on common real-world tasks.
In the year 2005, many people overfit some aspect of life. I prefer to use the term 'overfit' as opposed to overspecialize because it draws upon the context of regression (fitting). When each person is treated independently of others, overfitting can only be seen as a bad thing. When does one person really want a neural network to overfit? However, in the context of society's machine, overfits are the ones who expand the horizon of modern life. It is as if overfitting was brought about by evolution. Evolution probably favored species who steadily produced a small, yet non-infinitesimal, percent of overfitters. Since people can be seen as the cream of the crop with respect to many evolutionary metrics, it is of no surprise that we are overfitting so well.
Overfitters unite!
I think people can learn about themselves by studying machine learning. In a good article titled "The Parallel Distributed Processing Approach to Semantic Cognition" by James L. McClelland and Timothy T. Rogers, degradation of semantic knowledge in humans (a condition known as sementic dementia) was compared to the behavior of a neural network. Traditionally scientists would study humans in an attempt to develop better computational techniques for tasks such as machine learning and machine vision, but it is important to study computational techniques because they can tell us something about ourselves.
Thursday, September 29, 2005
reproducing kernel hilbert space
After a talk by Jean-Francois yesterday I decided to learn a little bit about RKHS: Reproducing Kernel Hilbert Space. So what's this new vector space that everybody is talking about?
The RKHS is easily grasped when one draws the analogy betwen role of the Dirac Delta in L2 and the reproducing kernel in a RKHS. The problem is that the dirac delta isn't in L2. Because of this property, the reproducing kernel of L2 isn't in L2. Due to the insanely small support size of the dirac delta, some non-smooth functions are in L2. In fact, we need two different notions of convergence for L2. We need convergence in the mean and pointwise convergence.
In an RKHS, convergence in the mean implies pointwise convergence. In an RKHS, the reproducing kernel usually has some support and therefore only smooth functions lie in this space. The reproducing kernel of an RKHS is actually in the RKHS! Great!
Did I get that right? I have to read Michael Jordan's notes again.
The RKHS is easily grasped when one draws the analogy betwen role of the Dirac Delta in L2 and the reproducing kernel in a RKHS. The problem is that the dirac delta isn't in L2. Because of this property, the reproducing kernel of L2 isn't in L2. Due to the insanely small support size of the dirac delta, some non-smooth functions are in L2. In fact, we need two different notions of convergence for L2. We need convergence in the mean and pointwise convergence.
In an RKHS, convergence in the mean implies pointwise convergence. In an RKHS, the reproducing kernel usually has some support and therefore only smooth functions lie in this space. The reproducing kernel of an RKHS is actually in the RKHS! Great!
Did I get that right? I have to read Michael Jordan's notes again.
Tuesday, September 27, 2005
its all about the Bayes Nets
Currently thinking about: Bayesian Networks.
Currently reading: Michael Jordan, Andrew Ng, Chris Bishop, Kevin C. Murphy.
Currently reading: Michael Jordan, Andrew Ng, Chris Bishop, Kevin C. Murphy.
Thursday, September 22, 2005
The soul and the extended phenotype
I had an interesting thought today when I was thinking about the 'soul' and machine learning. Today's epiphany revolves around two key ideas:
a.) why so many people in AI/Robotics are obsesed with Machine Learning (experience at CMU)
b.) how a particular genotype has broad impact on the rest of the world (Dawkins' Extended Phenotype)
Let's start with the evolutionary theory first. According to Richard Dawkins, the term 'extended phenotype' refers to the influence of a gene beyond the organism which is a container for the gene. Dawkins says that we have to look beyond the effects of a gene on the organism which serves as a container for the gene; we have to look at the cases where the gene influences the survival of an organism by its broad-reaching influence. In The Selfish Gene, Dawkins discusses interesting cases where a virus (with its own genes) will infect an organism and through its own extended phenotype it will help the the organism survive. This is a case where the virus helps the organism and the organism helps the virus.
Imagine this process of mutual symbiosis has been happening over millions of years as species evolved. In the same sense that Dawkins uses the term 'extended phenotype' to denote that the gene has a long reach outwards into the world, we can also look at the long reach of the world inwards. If the outside environment is made up of organisms which possess their own genes, then just as much as we are influencing them they are also influencing us. Over the insanely long amount of time that we have been evolving, the outside world has touched us deeply. We have acquired new genes simply because we are creatures which interact with the world (and the world interacts with us). There is a part of the outside world 'inside' us. This intimate relationship we have with the environment is a result of us evolving with the world. This pantheistic view that a part of the world is inside of us is what gives us our 'soul.'
Now I have something to say about Machine Learning. ML refers to algorithms that change their internal state once they observe some data. This is analogous to the process of the world becoming a part of us throughout the process of evolution. Machine Learning is concerned with algorithms that are trying really hard at building up a soul.
These esoteric ideas can be rendered pellucid via the artificial neural network analogy. An ANN contains hidden nodes whose weights are updated when new input/output pairs are presented. These weights are actually dependent on the input/output pairs. Sometimes these weights correspond to latent variables (hidden states) of the world, but it is only important to realize that these weights are highly correlated with the types of input/output pairs that have been used to update them. Consider person 'A' who spent their entire life in NYC (they were looking at buildings and crowded city scenes their entire life), and person 'B' who spent their entire life in the Sahara Desert (they were looking at sand dunes all of their life). Clearly, person 'B' will have a hard time getting their way around a metropolitan area while person 'A' will struggle at finding his/her way in any type of desert. This is because the spatio-temporal patterns that they have been accustomed to seeing have been engraved in their hidden weights. NYC is in some sense 'inside' of person 'A' while the Sahara is inside of person 'B'.
a.) why so many people in AI/Robotics are obsesed with Machine Learning (experience at CMU)
b.) how a particular genotype has broad impact on the rest of the world (Dawkins' Extended Phenotype)
Let's start with the evolutionary theory first. According to Richard Dawkins, the term 'extended phenotype' refers to the influence of a gene beyond the organism which is a container for the gene. Dawkins says that we have to look beyond the effects of a gene on the organism which serves as a container for the gene; we have to look at the cases where the gene influences the survival of an organism by its broad-reaching influence. In The Selfish Gene, Dawkins discusses interesting cases where a virus (with its own genes) will infect an organism and through its own extended phenotype it will help the the organism survive. This is a case where the virus helps the organism and the organism helps the virus.
Imagine this process of mutual symbiosis has been happening over millions of years as species evolved. In the same sense that Dawkins uses the term 'extended phenotype' to denote that the gene has a long reach outwards into the world, we can also look at the long reach of the world inwards. If the outside environment is made up of organisms which possess their own genes, then just as much as we are influencing them they are also influencing us. Over the insanely long amount of time that we have been evolving, the outside world has touched us deeply. We have acquired new genes simply because we are creatures which interact with the world (and the world interacts with us). There is a part of the outside world 'inside' us. This intimate relationship we have with the environment is a result of us evolving with the world. This pantheistic view that a part of the world is inside of us is what gives us our 'soul.'
Now I have something to say about Machine Learning. ML refers to algorithms that change their internal state once they observe some data. This is analogous to the process of the world becoming a part of us throughout the process of evolution. Machine Learning is concerned with algorithms that are trying really hard at building up a soul.
These esoteric ideas can be rendered pellucid via the artificial neural network analogy. An ANN contains hidden nodes whose weights are updated when new input/output pairs are presented. These weights are actually dependent on the input/output pairs. Sometimes these weights correspond to latent variables (hidden states) of the world, but it is only important to realize that these weights are highly correlated with the types of input/output pairs that have been used to update them. Consider person 'A' who spent their entire life in NYC (they were looking at buildings and crowded city scenes their entire life), and person 'B' who spent their entire life in the Sahara Desert (they were looking at sand dunes all of their life). Clearly, person 'B' will have a hard time getting their way around a metropolitan area while person 'A' will struggle at finding his/her way in any type of desert. This is because the spatio-temporal patterns that they have been accustomed to seeing have been engraved in their hidden weights. NYC is in some sense 'inside' of person 'A' while the Sahara is inside of person 'B'.
Sunday, September 18, 2005
google maps Shadyside jogging path
Here is a google maps plan of my Shadyside jogging path. I ran this route yesterday in about 35 minutes.
bidirectional search: looking for Marr
Unifying ↓↑ (bottom-up) and ↑↓ (top-down) approaches to computer vision reminds me of bidirectional search (an algorithm that is generally taught in introductory Articial Intelligence courses).
I need to find a copy of David Marr's book Vision. Or perhaps this book is already looking for me.
I need to find a copy of David Marr's book Vision. Or perhaps this book is already looking for me.
Wednesday, September 14, 2005
research advisor
Today I was officially bound to my research advisor, who obtained his PhD in 2003. The other person that I was debating working with obtained his PhD in 1974. Youth = passion = new ideas.
I came to CMU wanting to work on high level vision tasks such as object detection/recognition and machine learning, and now I'm doing it. I should start planning for the future; I'll be out of here in no time.
I have to start working on my new research webpage at CMU. I will then update my new research directions.
I came to CMU wanting to work on high level vision tasks such as object detection/recognition and machine learning, and now I'm doing it. I should start planning for the future; I'll be out of here in no time.
I have to start working on my new research webpage at CMU. I will then update my new research directions.
Tuesday, September 13, 2005
I love to approximate {functions,data} with other {functions,kernels}
Today was the first class of Machine Learning. This first-rate course is being taught by renown ML researchers Tom Mitchell and Andrew Moore. In fact, the primary text for the course was written in 1997 by Tom Mitchell.
Camera Calibration = unexciting
Parzen Density Estimation = exciting!
If you find yourself bored one day, take a look at the online book titled Linear Methods of Applied Mathematics: Orthogonal series, boundary-value problems, and integral operators. It's delicious.
Camera Calibration = unexciting
Parzen Density Estimation = exciting!
If you find yourself bored one day, take a look at the online book titled Linear Methods of Applied Mathematics: Orthogonal series, boundary-value problems, and integral operators. It's delicious.
Monday, September 12, 2005
Vision is not inverse optics
While thinking about the microstructure of rough materials and microfacet lighting models such as the Torrence-Sparrow or Oren-Nayar models, I came to the hypothetical epiphany that vision is not inverse optics.
I should clarify. There are two types of vision, namely computational human vision and computational extraterrestrial vision. Computational human vision is concerned with high level vision tasks such as object detection, object learning/discovery, and overall scene understanding. Computational extraterrestrial vision is concerned with understanding how light interacts with matter and how we can infer low level properties of substances given their images. We should look at this computational extraterrestrial vision goal as something that would help scientists see things that the naked eye cannot see. However, I vehemently protest the idea that we need anything like a Oren-Nayar lighting model to be able to do object detection in the way humans can do it.
When I was younger (4 years ago) I wanted to be a theoretical physicist. Back then I envisioned that in graduate school I would be writing simulations of quantum chromodynamics. I thought that by starting with small things (gluons, quarks, photons, electrons) I could one day help put together all of the pieces scientists have been collecting over the years. However, I have abandoned this goal of understanding the world via physics. I have little faith in the bottom-up approach to modeling reality.
I believe that by studying computational human vision, I am following the Top-Down approach to modeling reality. For a long time I've had this vision of a new quantum mechanics, a new physics where the indivisble units are 'cats' and 'trees' and 'cars,' namely the indivisible units of human experience.
I should clarify. There are two types of vision, namely computational human vision and computational extraterrestrial vision. Computational human vision is concerned with high level vision tasks such as object detection, object learning/discovery, and overall scene understanding. Computational extraterrestrial vision is concerned with understanding how light interacts with matter and how we can infer low level properties of substances given their images. We should look at this computational extraterrestrial vision goal as something that would help scientists see things that the naked eye cannot see. However, I vehemently protest the idea that we need anything like a Oren-Nayar lighting model to be able to do object detection in the way humans can do it.
When I was younger (4 years ago) I wanted to be a theoretical physicist. Back then I envisioned that in graduate school I would be writing simulations of quantum chromodynamics. I thought that by starting with small things (gluons, quarks, photons, electrons) I could one day help put together all of the pieces scientists have been collecting over the years. However, I have abandoned this goal of understanding the world via physics. I have little faith in the bottom-up approach to modeling reality.
I believe that by studying computational human vision, I am following the Top-Down approach to modeling reality. For a long time I've had this vision of a new quantum mechanics, a new physics where the indivisble units are 'cats' and 'trees' and 'cars,' namely the indivisible units of human experience.
I used to Aeolian, now I'm Dorian
My musical style has slightly changed as I now focus more on changing my modes while I play guitar instead of always going back to the Aeolian minor mode. I'm still playing the same notes, but I tend to focus a lot more on the minor7,major7,7 trio.
A few years back I was an Eminor-->Dmajor type of player. Then a few months I started dabbling in minor7 and major7 chords. I find myself often playing the following pattern that I found on wholenote (like I Will Survive by Cake):
Am7 Dm7 G7 Cmaj7 Fmaj7 Bbmaj7 Esus4 E
I tend to play a lot more Dorian than Aeolian these days.
A few years back I was an Eminor-->Dmajor type of player. Then a few months I started dabbling in minor7 and major7 chords. I find myself often playing the following pattern that I found on wholenote (like I Will Survive by Cake):
Am7 Dm7 G7 Cmaj7 Fmaj7 Bbmaj7 Esus4 E
I tend to play a lot more Dorian than Aeolian these days.
Saturday, September 10, 2005
A Race and A Purchase
Yesterday I participated in the Carnegie Mellon SCS Pretty Good Race. I placed 20th out of roughly 47 contestants. For about a half of a mile (the last stretch) I was a few feet behind some girl, but at the end I had enough juice left to sprint and pass her. Little did I know that she was the first girl to finish (6 seconds behind me).

I bought some new stylish running gear today at Dick's sporting goods store. Most importantly I bought new running shoes, namely Asics GT-2100 shoes. The box was improperly marked, so I only paid $59.99 instead of the normal $79.99 discount price ($89.99 when not on sale). I also bought a headband (to stop the nasty hair gel/sweat mixture from hurting my eyes while I run) and some expensive running shorts made out of some special fabric. Later that day I tested out my new gear. :-)

I bought some new stylish running gear today at Dick's sporting goods store. Most importantly I bought new running shoes, namely Asics GT-2100 shoes. The box was improperly marked, so I only paid $59.99 instead of the normal $79.99 discount price ($89.99 when not on sale). I also bought a headband (to stop the nasty hair gel/sweat mixture from hurting my eyes while I run) and some expensive running shorts made out of some special fabric. Later that day I tested out my new gear. :-)
Wednesday, September 07, 2005
seeing with our feet and hands: quantum mechanics for you
Can we see without moving around with our legs (the things responsible for allowing us to change our viewpoint with respect to a stationary object)? Can we see without our hands (which allow us to manipulate objects as to change our viewpoint)?
In the context of a computational theory of vision, can we truly expect an algorithm to understand what objects are if we keep feeding it images, never letting it explore the world? I've been mentally preparing myself for Alva Noe's book (see last post) by tring to think about what he is about to tell me. Can we have perception without action?
Then again, what do I know? I know that vision research has been stagnating for the past few decades. Why would I care what a philosopher at Berkeley has to say? Why not read vision papers? The answer not clear, but the expression that comes to mind is Kuhn's "paradigm shift." Something tells me that physics and philosophy are going to be a big parts of my future research. Unfortunately (fortunately perhaps) I will be forced to interact with the mainstream vision community.
Adieu
In the context of a computational theory of vision, can we truly expect an algorithm to understand what objects are if we keep feeding it images, never letting it explore the world? I've been mentally preparing myself for Alva Noe's book (see last post) by tring to think about what he is about to tell me. Can we have perception without action?
Then again, what do I know? I know that vision research has been stagnating for the past few decades. Why would I care what a philosopher at Berkeley has to say? Why not read vision papers? The answer not clear, but the expression that comes to mind is Kuhn's "paradigm shift." Something tells me that physics and philosophy are going to be a big parts of my future research. Unfortunately (fortunately perhaps) I will be forced to interact with the mainstream vision community.
Adieu
Tuesday, September 06, 2005
two books and a signature
After an oral examination with the professor, he decided that I was qualified to waive the Math Fundamentals for Robotics course. I did study. He could probably tell when he asked me "Do you know what the Calculus of Variations is?" and I replied, "Would you like to see the derivation or the Euler Lagrange equation?"
I went to the library and got two books. The first one is Shimon Edelman's Representation and Recognition in Vision. The second book is Alva Noe's Action in Perception. I was aroused by this book after reading Edelman's short reply to Action in Perception; this paper can be found here.
To quote Noe, "The main idea of this book is that perception isn't something that happens inside us (in our brains say). It is something we do." I feel that to push the field of computer vision to the next level, I must know what these philosophers are up to. A long time ago I could have been found in a philosophy class arguing about something pointless, but I shortly abandoned my futile project to fully dedicate my time to physics and computer science. After the code and the calculus, I believe that I have reached a level of maturity which allows me to revisit philosophy.
I went to the library and got two books. The first one is Shimon Edelman's Representation and Recognition in Vision. The second book is Alva Noe's Action in Perception. I was aroused by this book after reading Edelman's short reply to Action in Perception; this paper can be found here.
To quote Noe, "The main idea of this book is that perception isn't something that happens inside us (in our brains say). It is something we do." I feel that to push the field of computer vision to the next level, I must know what these philosophers are up to. A long time ago I could have been found in a philosophy class arguing about something pointless, but I shortly abandoned my futile project to fully dedicate my time to physics and computer science. After the code and the calculus, I believe that I have reached a level of maturity which allows me to revisit philosophy.
Monday, September 05, 2005
schooling algorithms: bringing babies to school
It appears that Google might not be the best source of data for training a machine vision system (a baby) in the early stages. I will use the word baby to loosely refer to the current state of the art in machine vision. Before a teenage vision algorithm can learn to navigate the nasty world on its own, it must learn the basics of vision and object classification in elementary school.
What I'm trying to say is that there is a time for everything; there is a time for unsupervised learning. Try using Google images to search for images of 'shoe' and you will find the third image a 10 foot high-heeled shoe. A human will understand that this is still a shoe even though its scale is out of whack. When trying to teach a baby what the word 'shoe' means, it is a bad idea to show it 10 fooot high statues of shoes.
By the way, Google images returns too many synthetic and manually edited images of objects. These unrealistic scenarios are not good for training babies.
What I'm trying to say is that there is a time for everything; there is a time for unsupervised learning. Try using Google images to search for images of 'shoe' and you will find the third image a 10 foot high-heeled shoe. A human will understand that this is still a shoe even though its scale is out of whack. When trying to teach a baby what the word 'shoe' means, it is a bad idea to show it 10 fooot high statues of shoes.
By the way, Google images returns too many synthetic and manually edited images of objects. These unrealistic scenarios are not good for training babies.
Saturday, September 03, 2005
Investing in America and Donating to Red Cross
I just donated 25$ to the Red Cross because of the Katrina debacle. I don't think 25$ is a lot, but I think that if a grad student living from a stipend can afford 25$ then affluent Americans can afford to donate a few more dollars. The funds will add up, I have faith in multiplication.
It's not like I'm simply giving away my money, I'm investing in America. I know there will be a time when some other part of America (perhaps the part where I reside) will require help, and I hope a similar mentality will drive some other graduate student on the other side of the US to donate his 25$ (and perhaps help me eat).
My friend Mark recently put up this http://robogradshelp.blogspot.com/ for robograds to donate to the Red Cross. This site is merely a gateway to the official Red Cross site. So far we have a few 1st year robograds who donated 25$.
It's not like I'm simply giving away my money, I'm investing in America. I know there will be a time when some other part of America (perhaps the part where I reside) will require help, and I hope a similar mentality will drive some other graduate student on the other side of the US to donate his 25$ (and perhaps help me eat).
My friend Mark recently put up this http://robogradshelp.blogspot.com/ for robograds to donate to the Red Cross. This site is merely a gateway to the official Red Cross site. So far we have a few 1st year robograds who donated 25$.
Thursday, September 01, 2005
python and google
I want to one day work for Google. And I want to write Python code while I'm there. It can happen.
I've been thinking about what I want my PhD to give me. Freedom is what I want. I don't want to work for anybody. We'll see how that goes.
I've been thinking about what I want my PhD to give me. Freedom is what I want. I don't want to work for anybody. We'll see how that goes.
Tuesday, August 30, 2005
Sushimania
300$ worth of sushi split between 12 people.
Boris arranged a sushi-eating event for the first year Robotics students. I've never eaten so much sushi in my life; it was a good time. Instead of sitting in the normal tables at Sushi Too in Shadyside we sat in a special section located upstairs. I never knew Sushi Too had an upstairs section. Even though we paid extra (~50$) for the special treatment, it was worth it.
Boris arranged a sushi-eating event for the first year Robotics students. I've never eaten so much sushi in my life; it was a good time. Instead of sitting in the normal tables at Sushi Too in Shadyside we sat in a special section located upstairs. I never knew Sushi Too had an upstairs section. Even though we paid extra (~50$) for the special treatment, it was worth it.
Wednesday, August 24, 2005
Umphrey's Mcgee
I just got back from an Umphrey's Mcgee show at Mr. Small's theatre in Pittsburgh. It was dank-a-licious! It was my frist time seeing them, and I'd rate the show as 8.3/10. It would have been more fun if I didn't go alone.
I'm very excited about Al Di Meola playing at Mr. Small's on October 1st. I also found out that String Cheese Incident will be playing on October 14th (a friday!!) in Carnegie Hall, and Particle on September 13th at Mr. Small's(I don't know if I'll go to this weekday show).
I'm very excited about Al Di Meola playing at Mr. Small's on October 1st. I also found out that String Cheese Incident will be playing on October 14th (a friday!!) in Carnegie Hall, and Particle on September 13th at Mr. Small's(I don't know if I'll go to this weekday show).
Tuesday, August 23, 2005
[Computer] Vision people are a waste of energy
At least Manuela Veloso thinks so. There are two types of people.
The first type doesn't do Vision because they never had a need to (The "what's Vision?" people, aka rustic folk). I don't have much to say about these people. The second type does Vision (aka the vision hacker). These people generally like to think about object recognition.
There are also two types of people who do Vision (maybe even consider it drudgery), but do not like to be called vision hackers (at least they don't hack on vision problems for vision's sake). I will call these people the non-vision people (but they do Vision, so they are not rustic folk).
Roboticists who have to deal with visual sensors are one type of Vision-doing non-vision people. They don't think that the Vision problem will be solved anytime soon, but they cannot escape the Vision problem alltogether. They are merely frustrated by the lack of development in vision in the past 30 years (nevertheless a warranted frustration), and the goal of their research is something which must use Vision (but are not obsessed with Vision like vision hackers). These people will generally say things like, "Do something productive" to Vision hackers.
We also have Machine Learning (ML folk) people who call Vision hackers people "the vision people" and they make the quotation mark gestures with their fingers when they call them that. These ML people think that Vision people are just doing Machine Learning but are living in some sort of denial.
The first type doesn't do Vision because they never had a need to (The "what's Vision?" people, aka rustic folk). I don't have much to say about these people. The second type does Vision (aka the vision hacker). These people generally like to think about object recognition.
There are also two types of people who do Vision (maybe even consider it drudgery), but do not like to be called vision hackers (at least they don't hack on vision problems for vision's sake). I will call these people the non-vision people (but they do Vision, so they are not rustic folk).
Roboticists who have to deal with visual sensors are one type of Vision-doing non-vision people. They don't think that the Vision problem will be solved anytime soon, but they cannot escape the Vision problem alltogether. They are merely frustrated by the lack of development in vision in the past 30 years (nevertheless a warranted frustration), and the goal of their research is something which must use Vision (but are not obsessed with Vision like vision hackers). These people will generally say things like, "Do something productive" to Vision hackers.
We also have Machine Learning (ML folk) people who call Vision hackers people "the vision people" and they make the quotation mark gestures with their fingers when they call them that. These ML people think that Vision people are just doing Machine Learning but are living in some sort of denial.
Monday, August 22, 2005
Love and Marriage
The Robotics Immigration Course started today. This week-long event is a mandatory orientation for incoming Robotics students (PhD/MS/MSIT) at CMU. I had a chance to visit the cubicle which will soon become my playground. Even though the arrangement of my cubicle is far from ideal, I'm somewhat excited about having a new computer to work with. At the end of the Robotics IC I have to create a list of desired Professors I want to work with; getting hooked up with a professor is known as "the marriage process" here at the Robotics Institute.
I started coding again. I'm going to work on a side project for a long time (because I'll only dedicate a few hours a week) and I don't plan on telling anybody about it.
I started coding again. I'm going to work on a side project for a long time (because I'll only dedicate a few hours a week) and I don't plan on telling anybody about it.
Sunday, August 21, 2005
Organic Food
Wholefoods has introduced itself into my world. From the pleasant shopping atmosphere to the friendly staff I was impressed.
Capitalism: The story of {a,my} life
Driven by ambition, shaped by competition, and mesmerized by greed; the story of my life is the story of a pawn. A pawn in the sense that my movement has been limited to one square at a time or two squares in the first move. From my life-long dreams to my daily academic hobbies, I have fallen victim to a deadly train of though, ie capitalism. Not a mere economic system, in which the means of production and distribution are privately or corporately owned and development is proportionate to the accumulation and reinvestment of profits gained in a free market (capitalism), but a lifestyle which is obsessed with value and the individual.
We should understand capitalism as a stage in our lives, a lesson we need to learn from. A friend of mine, g.eof(), said "Competition was fun to learn the game, but now that we can play it so well we ought to all be on the same team." Even though this is a very valuable statement, I don't think the world is ready for a new paradigm shift, ie "being on the same team." I believe that we will not be able to transcend capitalism until we all "learn the game." Even though capitalism is here in the United States, it is not yet everywhere. I think that we need to nurture this beast until the entire globe is covered by its muscular wing span before we can trample it. In some sense, the two complementary beliefs that we can one day undermine capitalism and that the entire world has to first learn how to play the game make me a vehement capitalist. If there are parts of the world as of August 2005 that are not passionately pursuing capitalist ideals, then what good is it being an anti-capitalist?
What's next? What new paradigm will usurp capitalism? Whatever the new system might be, it must utilize capitalism as a stepping stone.
We should understand capitalism as a stage in our lives, a lesson we need to learn from. A friend of mine, g.eof(), said "Competition was fun to learn the game, but now that we can play it so well we ought to all be on the same team." Even though this is a very valuable statement, I don't think the world is ready for a new paradigm shift, ie "being on the same team." I believe that we will not be able to transcend capitalism until we all "learn the game." Even though capitalism is here in the United States, it is not yet everywhere. I think that we need to nurture this beast until the entire globe is covered by its muscular wing span before we can trample it. In some sense, the two complementary beliefs that we can one day undermine capitalism and that the entire world has to first learn how to play the game make me a vehement capitalist. If there are parts of the world as of August 2005 that are not passionately pursuing capitalist ideals, then what good is it being an anti-capitalist?
What's next? What new paradigm will usurp capitalism? Whatever the new system might be, it must utilize capitalism as a stepping stone.
Wednesday, August 17, 2005
Semantic Information Hiding: Mary thinks Joe is intelligent, but how smart is she? Perhaps I am not smart enough to be called truly intelligent.=0110
The English language contains a lot of redundancy. If one chooses to convey some information X, there exists a collection of sentences {L1,...,Ln} that could express X. For example, replacing words with their synonyms is one such simple operation that doesnt not alter meaning. Consider a sentence L* that contains a word W', which has synonyms {W1,...,Wk}; then the replacement of W' with Wi, where W \in [1,k], does not alter the meaning X. Now for an example.
The statement "Tombone is smart" is semantically equivalent (up to a threshold) to "Tombone is intelligent." Imagine that I write a program called Propaganda to fetch thousands of random blogs (which will inevitably contain the words "smart" and "intelligent") and concatenate them into one gigantic blog. Inside this gigantic blog, everytime I encounter the word "smart" or "intelligent" I am free to replace one with the other or keep the original word. I perform my swaps whenever I see them necessary, and repost the blog on the web. I also write another program called InterpretBlog, which simply reads in this gigantic blog (which looks like a bunch of text that normal people would write on a daily basis such as rants, love stories, debates, etc). While reading in the gigantic blog, the InterpretBlog program writes another file. When InterpretBlog encounters the word "intelligent" it writes a 0, and when it encounters the word "smart" it writes a 1. This new file that InterpretBlog writes can be anything we desire such as an executable program, an image, a hidden message, or a Dickens novel (given that the number of "intelligent"s plus the number of "smart"s is large enough).
The point is that two hosts can communicate via hidden messages embedded into blogs.
An hour later:
After a bit of googling, I found that the scientific term which most accurately captures the essence of my idea is "Lexical Steganography." I found the following webpage on Lexical Steganography very helpful.
The statement "Tombone is smart" is semantically equivalent (up to a threshold) to "Tombone is intelligent." Imagine that I write a program called Propaganda to fetch thousands of random blogs (which will inevitably contain the words "smart" and "intelligent") and concatenate them into one gigantic blog. Inside this gigantic blog, everytime I encounter the word "smart" or "intelligent" I am free to replace one with the other or keep the original word. I perform my swaps whenever I see them necessary, and repost the blog on the web. I also write another program called InterpretBlog, which simply reads in this gigantic blog (which looks like a bunch of text that normal people would write on a daily basis such as rants, love stories, debates, etc). While reading in the gigantic blog, the InterpretBlog program writes another file. When InterpretBlog encounters the word "intelligent" it writes a 0, and when it encounters the word "smart" it writes a 1. This new file that InterpretBlog writes can be anything we desire such as an executable program, an image, a hidden message, or a Dickens novel (given that the number of "intelligent"s plus the number of "smart"s is large enough).
The point is that two hosts can communicate via hidden messages embedded into blogs.
An hour later:
After a bit of googling, I found that the scientific term which most accurately captures the essence of my idea is "Lexical Steganography." I found the following webpage on Lexical Steganography very helpful.
Monday, August 15, 2005
cvs update -Pd
Does anybody know what "cvs update -Pd" signifies? Well, it means that I'm back in the game.
 I miss ParaView, and the beauty of Kitware software. All I need to do now is make sure that ParaView,VXL, and VTK are updated (this will probably take the rest of the day). I'm excited about the new changes to ParaView for two reasons. Primarily there are always so many new changes because many people are working on it. Secondly, as long as high quality hackers like Mr. Brad King are contributing, I'm updating!
I miss ParaView, and the beauty of Kitware software. All I need to do now is make sure that ParaView,VXL, and VTK are updated (this will probably take the rest of the day). I'm excited about the new changes to ParaView for two reasons. Primarily there are always so many new changes because many people are working on it. Secondly, as long as high quality hackers like Mr. Brad King are contributing, I'm updating!
 I miss ParaView, and the beauty of Kitware software. All I need to do now is make sure that ParaView,VXL, and VTK are updated (this will probably take the rest of the day). I'm excited about the new changes to ParaView for two reasons. Primarily there are always so many new changes because many people are working on it. Secondly, as long as high quality hackers like Mr. Brad King are contributing, I'm updating!
I miss ParaView, and the beauty of Kitware software. All I need to do now is make sure that ParaView,VXL, and VTK are updated (this will probably take the rest of the day). I'm excited about the new changes to ParaView for two reasons. Primarily there are always so many new changes because many people are working on it. Secondly, as long as high quality hackers like Mr. Brad King are contributing, I'm updating!
Sunday, August 14, 2005
Edmond Dantés is a part of us all: On The Count of Monte Cristo
Monsieur Le Comte de Monte-Cristo is a deliciously evil protagonist. This gargantuan plot is nothing more than Newton's third law, for every action there is an equal and oppostie reaction. In brief, this tale is about vengeance. Despite his vehement determination for retribution, the Count is indeed an icon worthy of idolization.
On the Selfish Gene

Although written by a biologist, namely Richard Dawkins, the book The Selfish Gene has furnished me with many new ideas about evolving algorithms and the notion of Intelligent Design. These new ideas are centered around the idea of an evolving objective function.
An objective function measures how well something performs; an easy example is the mean squared error fitting function used to find a function that fits some data points. Genetic Algorithms/Genetic Programming are gradient free optimization techniques used to find a vector/algorithm that minimizes some objective function. However, this objective function must be engineered by the human if one of these evolutionary computational techniques is to work. An interesting question is, how can we understand the objective function that we (humans) are trying to minimize? In other words, how does nature measure how fit one individual is? If one can demonstrate that this objective function has remained fixed over time, then perhaps one might be justified in believing in Intelligent Design (perhaps Providence only engineered the perfect objective function, instead of creating man in his image). While reading The Selfish Gene, I started thinking about how we (humans) are more than victims of some vicious objective function. When other humans are viewed as part of our environment, then it's easy to see how they must be factored into the objective function. In other words, the fitness score that other humans give us must be factored into the overall objective function. Evidently, if humans are responsible for some part of the fitness score and humans have evolved over time, then the objective function must have evolved simultaneously.
I am interested in computational evolution because I believe this holds the key to object recognition. If humans (which evolved) are masters at object recognition, then why not utilize evolution to find an algorithm that can recognize objects? There is something lacking in the traditional formulation of Genetic Programming. First of all, GP theory does not help us define an objective function, namely the most important driving force of evolution. Secondly, I'm not convinced that haphazard crossovers are superior to mutations.
Harmonic Minor Scale
Striving to break out of the Major Mode soloing mentality, I've recently discovered the Harmonic Minor sound. I can't seem to memorize new scales; I need to understand them in relation to already learned scales, thus I found the To Harmonic and Melodic page rather insightful.
Now I view the the Minor (Aeolian) Scale as an extension of the Minor Pentatonic Scale, and the Harmonic Scale as a perturbation of the Aeolian Scale. Although I have yet to tackle the applicability of this new scale, I find its sound rather charming and exotic, much like the Hirojoshi scale.
Now I view the the Minor (Aeolian) Scale as an extension of the Minor Pentatonic Scale, and the Harmonic Scale as a perturbation of the Aeolian Scale. Although I have yet to tackle the applicability of this new scale, I find its sound rather charming and exotic, much like the Hirojoshi scale.
Free wireless in my apt
I hope I keep picking up this unencrypted wireless signal in my apartment until I get my own service.
The start of a blog.
I'm starting this blog for several reasons. Primarily, I want practice writing. Secondly, I want to be able to write down crazy ideas I have from time to time.
Back in 2001, when I was learning CSS and XHTML, I wrote my own code to maintain a web log but I stopped updating my log once the word "blog" was inaugurated into American vernacular. Now all these fancy templates will allow me to blog in style without the drudgery of HTML maintenance.
Back in 2001, when I was learning CSS and XHTML, I wrote my own code to maintain a web log but I stopped updating my log once the word "blog" was inaugurated into American vernacular. Now all these fancy templates will allow me to blog in style without the drudgery of HTML maintenance.
Subscribe to:
Posts (Atom)