Friday, December 29, 2006
running in patchogue
When I come home for the holidays I like to go running -- unfortunately it is rather dark around suburbia at night time. As opposed to Shadyside, you probably won't encounter any other joggers. Are Long Islanders just anti-running? Here is a link for my Patchogue jogging path.
Wednesday, December 20, 2006
semester complete
This past semester I've learned quite a few things. From experience I've learned that TAN trees (Tree Augmented Naive Bayes) is not really better than the Naive Bayes Classifier. I've also learned that if you have lots of training data, then simple things like the nearest neighbour classifier work really well.
I learned a lot of new material from Carlos Guestrin's Graphical Models class. Unlike other classes in the past, this one really did present me with a plethora of new material. Junction Trees (aka Clique Trees) are really cool for exact inference. It was also really nice to see approximate inference algorithms such as loopy belief propagation and generalized belief propagation in action. Overall I think I'll be able to apply some concepts from Conditional Random Fields and approximate inference into my own research in object recognition.
I also finished my Teaching Assistant requirement. I'm still amazed at the high quality of Martial Hebert's Computer Vision course -- the students that take that class are almost ready to start producing research papers in the field. If there is one thing that sticks out from that course is how a large number of seemingly distinct problems get linearized and formulated as eigenvalue problems.
On another, not I started reading Snow Crash by Neal Stephenson. Pretty standard cyberpunk/hacker literature -- reminds me of World of Warcraft even though I've never played the game. I like it very much so far -- I should be done in a couple of days.
I learned a lot of new material from Carlos Guestrin's Graphical Models class. Unlike other classes in the past, this one really did present me with a plethora of new material. Junction Trees (aka Clique Trees) are really cool for exact inference. It was also really nice to see approximate inference algorithms such as loopy belief propagation and generalized belief propagation in action. Overall I think I'll be able to apply some concepts from Conditional Random Fields and approximate inference into my own research in object recognition.
I also finished my Teaching Assistant requirement. I'm still amazed at the high quality of Martial Hebert's Computer Vision course -- the students that take that class are almost ready to start producing research papers in the field. If there is one thing that sticks out from that course is how a large number of seemingly distinct problems get linearized and formulated as eigenvalue problems.
On another, not I started reading Snow Crash by Neal Stephenson. Pretty standard cyberpunk/hacker literature -- reminds me of World of Warcraft even though I've never played the game. I like it very much so far -- I should be done in a couple of days.
Wednesday, December 06, 2006
CVPR 2007: submitted!
Recently I submitted my first research paper to CVPR 2007. This is my first research paper where I'm first author (I had one from RPI where I was the 2nd author). Unfortunately I can't put a link up since it has to go through anonymous reviews.
On another note, the next conference I'm aiming for is ICCV in Brazil!
On another note, the next conference I'm aiming for is ICCV in Brazil!
Tuesday, November 07, 2006
segmentation as inference in a graphical model
Recently, I've been playing with the idea of obtaining an image segmentation by inference on a random field. For a Probabilistic Graphical Models final class project, my teammate and I have been using Conditional Random Fields for segmentation. By posing segmentation as a superpixel labelling problem and placing a random field structure over the class posterior distribution, we were able to obtain cool looking segmentations.

On another note, did you know that logistic regression can be viewed as a conditional random field with one output variable? Once you see this, then you'll never forget why logistic regression looks the way it does. Maybe you should read this really cool CRF tutorial.

On another note, did you know that logistic regression can be viewed as a conditional random field with one output variable? Once you see this, then you'll never forget why logistic regression looks the way it does. Maybe you should read this really cool CRF tutorial.
Wednesday, October 25, 2006
are you a frequentist? (Bayesianism vs Frequentism)
The answer is either a crisp yes (if you are one of those), or a fuzzy probably-not. As Carlos pointed out in Graphical Models class today, if you are a bayesianist then you would attribute a probability in (0,1) to you being a bayesianist.
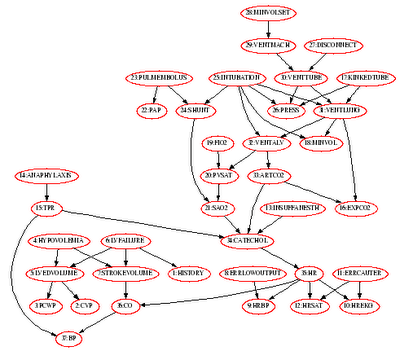
On another note, I'm finishing up yet another excruciating Probabilistic Graphical Models homework. This time, we had to implement variable elimination for exact inference in bayesian networks. Additionally, we implemented the min-fill heuristic to find a good variable elimination ordering. The 37 node alarm network is depicted above (graphviz baby!). I wonder if my variable elimination code is good enough to work on 1000 node networks. Only one way to find out. :-)
On another note, I've been practicing Milonga del Angel by Astor Piazzolla on my classical guitar.

On another note, I'm finishing up yet another excruciating Probabilistic Graphical Models homework. This time, we had to implement variable elimination for exact inference in bayesian networks. Additionally, we implemented the min-fill heuristic to find a good variable elimination ordering. The 37 node alarm network is depicted above (graphviz baby!). I wonder if my variable elimination code is good enough to work on 1000 node networks. Only one way to find out. :-)
On another note, I've been practicing Milonga del Angel by Astor Piazzolla on my classical guitar.
Wednesday, September 27, 2006
First half-lecture in front of a class
Yesterday I taught my first half-lecture for Martial's Computer Vision class. He was out of town, and we (the TAs) had to go over some new class material and go over the last/current homeworks. I think it went well.
Monday, September 18, 2006
textonify: texture classification with filters
A really good resource for vision researchers interested in texture-based classification is the Visual Geometry Group Texture Classification With Filters page.
For your enjoyment, here is a textonmap image:
For your enjoyment, here is a textonmap image:
Saturday, September 02, 2006
Burton Clash 158
Today I purchased my first snowboard; a Burton Clash 158! I can't wait to try it out this winter season.

Friday, September 01, 2006
visual class recognition inside a bounding box

Let's consider the problem of determining the object class that is located inside a bounding box?
Consider the PASCAL 2006 Visual Object Classes:
{'bicycle' 'bus' 'car' 'cat' 'cow' 'dog' 'horse' 'motorbike' 'person' 'sheep'}
If we use boosted decision trees to train a classifier that returns a posterior distribution over visual object classes given the size of the bounding box as input, how well can we expect our classifier to perform?
Surprisingly, it ends up that for the PASCAL 2006 'trainval' dataset, if we train such a classifier we are able to get a test rate of 40% correct. Given no information we expect a 10% accuracy rate for 10 object classes( This is just like guessing randomly; you're correct 10% of the time), so 40% is decent given that the classifier didn't actually get any appearance features from the interior of the bounding box.
If we look at the separate visual classes and look at the boosted decision tree performance for that visual class, we see something rather interesting:
'bicycle' 0.2139
'bus' 0.0242
'car' 0.5973
'cat' 0.1714
'cow' 0.0314
'dog' 0.1381
'horse' 0.0760
'motorbike' 0.0375
'person' 0.8327
'sheep' 0.1472
This means that the bounding box dimensions are highly discriminative for
the person and car classes. 83% of the bounding boxes containing a person were given the correct label by the classifier! However, since people are generally standing it is not too surprising to realize that the height of a person bounding box is generally much larger than its width and generally in a similar ratio.

Saturday, August 19, 2006
Computer Vision TA + discovering music that I like
This upcoming semester I'll be one of the two Teaching Assistants for Martial Hebert's Computer Vision class. (The other TA will be Ankur Datta) Most Robotics PhD students take this graduate course to satisfy their perception requirement. Since the 1st semester of the 1st year is a very popular time to take this course (at least it was a popular time for my incoming class), this opportunity will give me a chance to meet the new Robograds.
On another note, I recently out about Pandora Internet Radio, which I have been listening to over the past few days. On this website, you input a favourite song or artist and a radio station is automatically created to match your interests in music. You can then vote for the songs that you heard. The basic idea is to get introduced to music you've never heard but you should enjoy. Another great source for internet radio is Shoutcast and archive.org (download live shows or just stream them!).
On another note, I recently out about Pandora Internet Radio, which I have been listening to over the past few days. On this website, you input a favourite song or artist and a radio station is automatically created to match your interests in music. You can then vote for the songs that you heard. The basic idea is to get introduced to music you've never heard but you should enjoy. Another great source for internet radio is Shoutcast and archive.org (download live shows or just stream them!).
Thursday, August 03, 2006
Latent Dirichlet Allocation + Logistic-Normal + Detecting Objects
As a Robotics PhD student at Carnegie Mellon University, I took a Computer Vision course called "Advanced Perception." This Machine Learning-intensive course was taught by Alexei (Alyosha) Efros and my final project was all about detecting objects using a variant of Latent Dirichlet Allocation.

Jonathan Huang and I (Tomasz Malisiewicz) created these documents. So if you are into object recognition or just into bayesian hierarchical models you can check out these docs:
Detecting Objects via Multiple Segmentations and Latent Topic Models
Correlated Topic Model Details
You can also download some MATLAB code that Jon put up on the web:
fitting a Hierarchical Logistic-Normal distribution
You can also download our MATLAB Latent Dirichlet Allocation implementation (variational inference)
Enjoy!
Jonathan Huang and I (Tomasz Malisiewicz) created these documents. So if you are into object recognition or just into bayesian hierarchical models you can check out these docs:
Detecting Objects via Multiple Segmentations and Latent Topic Models
Correlated Topic Model Details
You can also download some MATLAB code that Jon put up on the web:
fitting a Hierarchical Logistic-Normal distribution
You can also download our MATLAB Latent Dirichlet Allocation implementation (variational inference)
Enjoy!
karamazov
Yesterday I started reading The Brothers Karamazov by Fyodor Dostoyevsky. Last summer I read The Count of Monte Cristo and I really enjoyed it, thus I decided to start another great classic. I wasn't impressed with the ending of Ishmael and decided that I wanted to read something that passed the test of time.
Wednesday, July 05, 2006
normalized cuts on an image of a cat

This is an image of a cat from the MSRC Image Database.

The segmentation engine used here is normalized-cuts; however, what you see here is not the raw output of normalized-cuts.
Friday, June 30, 2006
congrats to "Putting Objects in Perspective" and Geometric Context
Congratulations to Derek, Alexei, and Martial for getting their work Slashdotted and winning this year's Best Paper Award at CVPR in New York City. This work reinforces the fact that Carnegie Mellon University (especially The Robotics Institute) is the place you want to be if you want to study Computer Vision (and/or Machine Learning).
The work which won the Best Paper Award at CVPR is titled "Putting Objects in Perspective".
Quoting Derek's project description, "Image understanding requires not only individually estimating elements of the visual world but also capturing the interplay among them. We provide a framework for placing local object detection in the context of the overall 3D scene by modeling the interdependence of objects, surface orientations, and camera viewpoint. Most object detection methods consider all scales and locations in the image as equally likely. We show that with probabilistic estimates of 3D geometry, both in terms of surfaces and world coordinates, we can put objects into perspective and model the scale and location variance in the image. Our approach reflects the cyclical nature of the problem by allowing probabilistic object hypotheses to refine geometry and vice-versa. Our framework allows painless substitution of almost any object detector and is easily extended to include other aspects of image understanding."
The slashdot story link(June 14th) can be found here:
The work which won the Best Paper Award at CVPR is titled "Putting Objects in Perspective".
Quoting Derek's project description, "Image understanding requires not only individually estimating elements of the visual world but also capturing the interplay among them. We provide a framework for placing local object detection in the context of the overall 3D scene by modeling the interdependence of objects, surface orientations, and camera viewpoint. Most object detection methods consider all scales and locations in the image as equally likely. We show that with probabilistic estimates of 3D geometry, both in terms of surfaces and world coordinates, we can put objects into perspective and model the scale and location variance in the image. Our approach reflects the cyclical nature of the problem by allowing probabilistic object hypotheses to refine geometry and vice-versa. Our framework allows painless substitution of almost any object detector and is easily extended to include other aspects of image understanding."
The slashdot story link(June 14th) can be found here:
Researchers Teach Computers To Perceive 3D from 2D
Tuesday, June 27, 2006
what is segmentation?
What is segmentation?
According to the computer vision community, a segmentation is a disjoint partition of an image into K regions. Popular segmentation strategies include (but are not limited to): normalized cuts, graph cuts, mean-shift, watershed. Researches sometimes use the outputs of these 'segmentation engines' in the middle of their own algorithm. However, according to Jitendra Malik (paraphrased from CVPR 2006) segmentation is the result of recognition and not that disjoint partition that is returned by your favorite 'segmentation engine'.
Perhaps Jitendra would prefer to call these 'segmentation engines' something else such as 'hypothetical perceptual grouping' engine. I would have to agree with Jitendra that segmentation is what we want at the end of recognition.
According to the computer vision community, a segmentation is a disjoint partition of an image into K regions. Popular segmentation strategies include (but are not limited to): normalized cuts, graph cuts, mean-shift, watershed. Researches sometimes use the outputs of these 'segmentation engines' in the middle of their own algorithm. However, according to Jitendra Malik (paraphrased from CVPR 2006) segmentation is the result of recognition and not that disjoint partition that is returned by your favorite 'segmentation engine'.
Perhaps Jitendra would prefer to call these 'segmentation engines' something else such as 'hypothetical perceptual grouping' engine. I would have to agree with Jitendra that segmentation is what we want at the end of recognition.
Sunday, June 18, 2006
CVPR
I returned from Poland this past Thursday, and I attented the first day of CVPR yesterday. On this first day, I went to the "Beyond Patches" workshop; however, the most exciting part of the conference will be tomorrow through Wednesday.
Also, I've started reading Ishmael by Daniel Quinn. I think there are some interesting topics being discussed in Ishmael and should be compared to the ideas presented in Isaac Asimov's Foundation series. When I finish Ishmael, I will write more on this.

Also, I've started reading Ishmael by Daniel Quinn. I think there are some interesting topics being discussed in Ishmael and should be compared to the ideas presented in Isaac Asimov's Foundation series. When I finish Ishmael, I will write more on this.

Monday, June 05, 2006
Greetings!
Greetings from Wloclawek, Poland. I'm currently sitting in an internet cafe checking up on my email. I finished Dan Brown's DaVinci Code, and am currently reading Kurt Vonnegut's Slaughterhouse Five.
-T
-T
Wednesday, May 31, 2006
Two weeks in Poland
Currently I'm packing for my two week trip to Poland. After this little adventure, I'll be going to CVPR in NYC. By the end of June I'll be back in Shadyside, PA.
Friday, May 26, 2006



Friday, May 12, 2006
the killer app of computer vision
What is the killer application of computer vision? In other words, how useful are machines that can visually detect objects in images?
The easiest application to think of is image retrieval. For this application a user specifies either an image or some text, and the system returns new images that are somehow related to the input. In addition, the resulting images also come with some type of information that relates them to the input. Surely companies like Google would be interested in such applications, but isn't there more that we could get out of computer vision?
When I was younger I was very interested in particle physics, and I even finished my undergrad with a dual degree in Computer Science and Physics. I was impressed with the way that computational techniques could be used to 'get at' the world. Large-scale simulations and data analysis could be used to infer the structure of the world (or at least given some structure to fit the necessary parameters).
Could we train machines that can infer relationships between objects in the world? Can a machine infer Newtonian-like properties (and thus establish a metaphysics) of the world such as mass and gravity from visual observations? I think the big questions here is the folllowing: can we train machines to 'see' objects without those machines first understanding any properties of the dynamic world? When I say 'properties of the dynamic world,' I do not mean appearance variations, but things like 'objects have mass and things with mass do not just float in ambient space,' and 'things in motion tend to stay in motion.'
The easiest application to think of is image retrieval. For this application a user specifies either an image or some text, and the system returns new images that are somehow related to the input. In addition, the resulting images also come with some type of information that relates them to the input. Surely companies like Google would be interested in such applications, but isn't there more that we could get out of computer vision?
When I was younger I was very interested in particle physics, and I even finished my undergrad with a dual degree in Computer Science and Physics. I was impressed with the way that computational techniques could be used to 'get at' the world. Large-scale simulations and data analysis could be used to infer the structure of the world (or at least given some structure to fit the necessary parameters).
Could we train machines that can infer relationships between objects in the world? Can a machine infer Newtonian-like properties (and thus establish a metaphysics) of the world such as mass and gravity from visual observations? I think the big questions here is the folllowing: can we train machines to 'see' objects without those machines first understanding any properties of the dynamic world? When I say 'properties of the dynamic world,' I do not mean appearance variations, but things like 'objects have mass and things with mass do not just float in ambient space,' and 'things in motion tend to stay in motion.'
Sunday, May 07, 2006
first year of graduate school: lessons learned
A few days ago I went to the final class of my first year of graduate school. I just finished (well a few things are still due; however, I have no more classes) the first year of the Robotics PhD program at Carnegie Mellon University.
My first semester I took Appearance Modeling (graphics/vision course) and Machine Learning. This past semester I took Advanced Perception (aka vision 2) and Kinematics, Dynamics &Control (robot/physics course). In addition to these courses, I have been regularly attending CMU's Computer Vision misc-read reading group. I have also had the opportunity to collaborate with many other graduate students on course projects.
The course projects that I worked on are:
Demultiplexing Interreflections with Jean-Francois
Modeling Text Corpora with Latent Dirichlet Allocation with Jon
Learning to Walk without a Leash with Geoff and Mark
Detecting Objects with Multiple Segmentations and Latent Dirichlet Allocation with Jon
I probably learned the most amount of new concepts from the Machine Learning community. Graphical models are definitely very trendy in Computer Vision in 2006. Almost everyone wants to be Bayesian about random variables. After this first year of graduate school, I've expanded my vocabulary to include terms from topics such as: SVMs, kernel methods, spectral clustering, manifold learning, graphical models, texton-based texture modeling, boosting, MCMC, EM, density estimation, pLSA, variational inference, gibbs sampling, RKHS...
However, the one key piece of advice that I keep hearing over and over is the following:
Do not blindly throw Machine Learning algorithms at a vision problem in order to beat the performance of an existing algorithm.
I don't think I'll stray away from Machine Learning; however, it is very important to understand what a Machine Learning algorithm is doing and when it works/fails. On another note, next semester I'm taking Carlos Guestrin's Probabilistic Graphical Models course.
My first semester I took Appearance Modeling (graphics/vision course) and Machine Learning. This past semester I took Advanced Perception (aka vision 2) and Kinematics, Dynamics &Control (robot/physics course). In addition to these courses, I have been regularly attending CMU's Computer Vision misc-read reading group. I have also had the opportunity to collaborate with many other graduate students on course projects.
The course projects that I worked on are:
Demultiplexing Interreflections with Jean-Francois
Modeling Text Corpora with Latent Dirichlet Allocation with Jon
Learning to Walk without a Leash with Geoff and Mark
Detecting Objects with Multiple Segmentations and Latent Dirichlet Allocation with Jon
I probably learned the most amount of new concepts from the Machine Learning community. Graphical models are definitely very trendy in Computer Vision in 2006. Almost everyone wants to be Bayesian about random variables. After this first year of graduate school, I've expanded my vocabulary to include terms from topics such as: SVMs, kernel methods, spectral clustering, manifold learning, graphical models, texton-based texture modeling, boosting, MCMC, EM, density estimation, pLSA, variational inference, gibbs sampling, RKHS...
However, the one key piece of advice that I keep hearing over and over is the following:
Do not blindly throw Machine Learning algorithms at a vision problem in order to beat the performance of an existing algorithm.
I don't think I'll stray away from Machine Learning; however, it is very important to understand what a Machine Learning algorithm is doing and when it works/fails. On another note, next semester I'm taking Carlos Guestrin's Probabilistic Graphical Models course.
Monday, April 17, 2006
localizing sheep
 Here are our top 9 sheep detections sorted by a primitive confidence value. The dotted green bounding box is our result and the ground truth label is in yellow. Note that our top 9 sheep detections are all true positives.
Here are our top 9 sheep detections sorted by a primitive confidence value. The dotted green bounding box is our result and the ground truth label is in yellow. Note that our top 9 sheep detections are all true positives.Saturday, April 15, 2006
no longer waiting to hear about NDSEG fellowship...
No longer waiting to hear back about the NDSEG fellowship...(note the title changed) There's a good chance that you are reading this because you googled something like "NDSEG blog," so don't think that you haven't heard back because you simply didn't win. As of April 15th, I don't know anyone who heard back from NDSEG. Good luck all! We will find out soon enough.
As of April 28th, everybody that I know who has applied already heard back.
Update: some people heard back (positive replies!) last Friday (the Friday following April 15th)
Update++: I didn't win the NDSEG fellowship; however, I'm still quite happy with winning the NSF fellowship.
As of April 28th, everybody that I know who has applied already heard back.
Update: some people heard back (positive replies!) last Friday (the Friday following April 15th)
Update++: I didn't win the NDSEG fellowship; however, I'm still quite happy with winning the NSF fellowship.
Thursday, April 13, 2006
being bayesian about DNA: encoding hyperparameters?
During one's lifetime, one will have to learn how to accomplish many different tasks. How different are all of these learning problems? As of 2006, researchers have broken up the field of artificial intelligence into subfields which study particular learning problems such as: vision, path planning, and manipulation. These are all examples of tasks at which human excel without any hardship. Should researchers be studying these problems independently? One can imagine that the human's intellect consists of many modules which are responsible for learning how to do all of the magnificent things that we do. One can proceed to be Bayesian about this learning architecture and somehow relate these learning modules hierarchically via some type of prior. Perhaps researchers should be studying Machine Learning architectures that allow a system to rapidly learn how to solve novel problems once it has solved other (similar?) problems.
Throughout one's life, the learning modules will be at work and over time reach some 'state.' (One can think of this 'state' as an assignment of values to some nodes in a Bayesian Hierarchical Model). However, this state is a function of one's experiences and isn't anything that can be passed on from one generation to another. We all know that one cannot pass down what they learned via reproduction. Then what are we passing down from one generation to another?
The reason why the state of a human's brain cannot be passed down is that it simply won't compress down into anything small enough that can fit inside of a cell. However, the parameters of the prior associated with all of these learning problems [that a person solves throughout their life] is a significantly smaller quantity that can be compressed down to the level of a cell. One can view DNA as a capsule that contains these hyperparameters. Once passed down from one generation to another, these parameters would determine how likely one is going to be; however, the state of the new brain will have be filled in again from experience in the real world.
Since evolution is governed by a high level of stochasticity then one can view nature as performing a gradient-free search through the space of all hyperparameters. How does nature evaluate the performance of a given hyperparameter value? Well, each human (an instantiation of those hyperparamters) works up to a 'state' and his/her survival/reproduction contribute to the score of that hyperparameter setting.
Throughout one's life, the learning modules will be at work and over time reach some 'state.' (One can think of this 'state' as an assignment of values to some nodes in a Bayesian Hierarchical Model). However, this state is a function of one's experiences and isn't anything that can be passed on from one generation to another. We all know that one cannot pass down what they learned via reproduction. Then what are we passing down from one generation to another?
The reason why the state of a human's brain cannot be passed down is that it simply won't compress down into anything small enough that can fit inside of a cell. However, the parameters of the prior associated with all of these learning problems [that a person solves throughout their life] is a significantly smaller quantity that can be compressed down to the level of a cell. One can view DNA as a capsule that contains these hyperparameters. Once passed down from one generation to another, these parameters would determine how likely one is going to be; however, the state of the new brain will have be filled in again from experience in the real world.
Since evolution is governed by a high level of stochasticity then one can view nature as performing a gradient-free search through the space of all hyperparameters. How does nature evaluate the performance of a given hyperparameter value? Well, each human (an instantiation of those hyperparamters) works up to a 'state' and his/her survival/reproduction contribute to the score of that hyperparameter setting.
Tuesday, April 11, 2006
cow and the new warmth
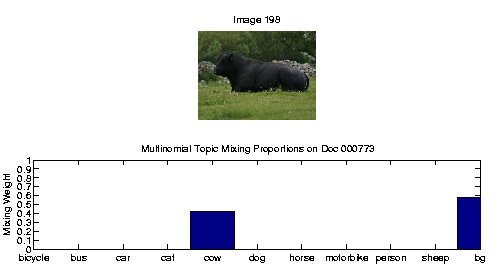
The above bar graph displays the topic mixing proportions for the image above. Clearly, the cow has been detected in an image classification sense (contains cow or not); however, we still have to see how well we are localizing the cow.
On another note, the weather has started getting nicer in Pittsburgh. I really miss late night walks around Shadyside when the weather in exceedingly warm. In a few days I'll know how well we (Jon and I) do on the CMU-level PASCAL challenge; I need to spend more time in the local park.
Finally, I've been trying to understand why I'm good at difficult things. I guess I both like the challenge and I like to work hard; however, it's not healthy to view all of life as a sequence of challenges that one can simply overcome with hard work. It takes some thought into deciding which challenges are worthy and which ones aren't worthy of pursuit; it's even more difficult deciding which ones can and which ones cannot be overcome with hard work. Life is mysterious because it occasionally presents one with challenges that require more of 'a cool air' around you than anything close to hard work. CGA said something along these lines during class a few months ago, "If you really want something, sometimes you have to step back." In conclusion, apparant lack of motivation for accomplishing a task doesn't necessarily imply a lack of desire for obtaining that goal; sometimes stepping back should be thought of as a regrouping stage -- a period of time during which one can refine their strategy and either come back with double the momentum or find a new problem to address.
Monday, April 10, 2006

Saturday, April 08, 2006
Finding Sheep -> Pigs on the Wing?

In a latent topic model (aspect model), each document has an associated distribution over latent topics (the mixing proportions). Here, the topics of the scene are mostly composed of the grass and sheep topic.
The mixing proportions on the graph above were obtained using the variational inference procedures that Jon and I wrote for our MATLAB implementation of Latent Dirichlet Allocation.
Wednesday, April 05, 2006
segmentation is not a k-way partition of an image
I have been recently working with Jon on a latent topic model for simultaneous object detection and segmentation. We are studying the use of a certain type of Hierarchical Bayesian Model (a variant of Blei's Latent Dirichlet Allocation) with dense image features (to be described in the near future) and applying our algorithm to the 2006 PASCAL Visual Object Classes Challenge.
Since I've been introduced to DDMCMC for image segmentation, I have been thinking about the relationship between segmentation and recognition. Also, in my Advanced Perception course, we recently looked at some Borenstein/Ullman papers that incorporate segmentation and recognition into one framework (this resulted in a few more ideas). Here are some short ideas about segmentation:
How is the problem of segmentation usually posed? Given an image, produce a partition of the image into K disjoint regions. If one wants to only use the image data given with no object-level assumptions, then one can only proceed to find the maximum likelihood segmentation. However, such a segmentation will have a very large variance (and a small bias) because there are many different ways of 'grouping' local image structures together.
Fortunately, one can be Bayesian and relate the 'seemingly independent' problems of segmenting different images by utilizing a prior over image regions. When employing a Bayesian Hierarchical model, one generally breaks down the problem into two stages: parameter estimation(training) and statistical inference(testing). Just like in the LDA model, parameter estimation is concerned with estimating the hyperparameters of the hierarchical model (and also finding the distributions over latent variables for each document in the training set) and inference is segmenting a novel image (by utilizing the parameters obtained in the training stage). By being Bayesian, one will introduce bias when segmenting a novel image (the bias will make the novel segmentation more like some of the segmentations that were obtained for the training corpus) and reduce variance. Isn't bias a good thing in this case? Don't we REALLY want a novel segmentation to be somehow related to other segmentations? Perhaps the only property about a segmentation engine that we care about is its object-level consistency across a wide number of images. We hope that: given a large enough training corpus that captures large variability in pose and appearance for a large number of objects, the 'semantic'-segmentation that is desired will be the one that is approximated with our hierarchical model. A latent topic-based segmentation engine would additionaly provide a registration across image features via the latent topic space. In other words, semantically equivalent image primitives would be near each other in some high dimensional latent-topic parameter space.
The new question should be: How can we learn to segment novel images given a corpus of images that are somehow related? Under this view, a segmentation of a novel image is a k-way parition of an image AND the latent topic distributions associated with each segment (registration of segments across images). Remember, object tracking is temporal registration and object recognition is semantic registration.
Since I've been introduced to DDMCMC for image segmentation, I have been thinking about the relationship between segmentation and recognition. Also, in my Advanced Perception course, we recently looked at some Borenstein/Ullman papers that incorporate segmentation and recognition into one framework (this resulted in a few more ideas). Here are some short ideas about segmentation:
How is the problem of segmentation usually posed? Given an image, produce a partition of the image into K disjoint regions. If one wants to only use the image data given with no object-level assumptions, then one can only proceed to find the maximum likelihood segmentation. However, such a segmentation will have a very large variance (and a small bias) because there are many different ways of 'grouping' local image structures together.
Fortunately, one can be Bayesian and relate the 'seemingly independent' problems of segmenting different images by utilizing a prior over image regions. When employing a Bayesian Hierarchical model, one generally breaks down the problem into two stages: parameter estimation(training) and statistical inference(testing). Just like in the LDA model, parameter estimation is concerned with estimating the hyperparameters of the hierarchical model (and also finding the distributions over latent variables for each document in the training set) and inference is segmenting a novel image (by utilizing the parameters obtained in the training stage). By being Bayesian, one will introduce bias when segmenting a novel image (the bias will make the novel segmentation more like some of the segmentations that were obtained for the training corpus) and reduce variance. Isn't bias a good thing in this case? Don't we REALLY want a novel segmentation to be somehow related to other segmentations? Perhaps the only property about a segmentation engine that we care about is its object-level consistency across a wide number of images. We hope that: given a large enough training corpus that captures large variability in pose and appearance for a large number of objects, the 'semantic'-segmentation that is desired will be the one that is approximated with our hierarchical model. A latent topic-based segmentation engine would additionaly provide a registration across image features via the latent topic space. In other words, semantically equivalent image primitives would be near each other in some high dimensional latent-topic parameter space.
The new question should be: How can we learn to segment novel images given a corpus of images that are somehow related? Under this view, a segmentation of a novel image is a k-way parition of an image AND the latent topic distributions associated with each segment (registration of segments across images). Remember, object tracking is temporal registration and object recognition is semantic registration.
Thursday, March 30, 2006
2006 National Science Foundation Graduate Research Fellowship
Today I found out that I won the 2006 NSF Graduate Research Fellowship! Last year I won Honorable Mention, so the big question is "What did I do differently this time around?" The short answer is, "I wrote awesome essays that addressed the NSF Merit Review Criteria of Intellectual Merit and Broader Impacts."
I felt like I was writing a somewhat non-technical introduction to my thesis when I was writing the proposed research essay. If I know you and you think that reading my essays (old ones got Honorable Mention and new ones got The Award) will be useful when you are applying for the NSF GRF this upcoming fall, then get in touch with me. NOTE: Only if I already know you or you go to the Robotics Institute at CMU will I help you out. In other words, if you are thinking of emailing me with the hope of getting my essays than don't even bother.
I'm still waiting to hear back from the NDSEG fellowship. On another note (slightly old news):
Alexei Efros(My research advisor) won an NSF Career Award and his other vision student, Derek Hoiem, won a Microsoft Fellowship.
I felt like I was writing a somewhat non-technical introduction to my thesis when I was writing the proposed research essay. If I know you and you think that reading my essays (old ones got Honorable Mention and new ones got The Award) will be useful when you are applying for the NSF GRF this upcoming fall, then get in touch with me. NOTE: Only if I already know you or you go to the Robotics Institute at CMU will I help you out. In other words, if you are thinking of emailing me with the hope of getting my essays than don't even bother.
I'm still waiting to hear back from the NDSEG fellowship. On another note (slightly old news):
Alexei Efros(My research advisor) won an NSF Career Award and his other vision student, Derek Hoiem, won a Microsoft Fellowship.
Saturday, March 25, 2006
what is segmentation? lessons from DDMCMC
On the desktop of my windows-based laptop there exists a text file titled "Reforming Segmentation," which discusses how the only way to get segmentation algorithms to do what we really want is by incorporating machine learning techniques into vision.
Coming soon...
Coming soon...
Monday, March 20, 2006
segmenting horses

Here is a sample image generated from my current research endeavours. Basically I'm trying to segment out the horse using a small number of segments (here the number of segments is 4). The images are sorted from best to worst (using a ground truth segmentation image).
I'll describe what I'm trying to do in future blog entries.
To summarize the horse dataset, here is the mean image in RGB-space of Eran Borenstein's Weizmann horse database:

Wednesday, March 15, 2006
montreal
Greetings World!
-Currently chilling in Montreal.
-Be be back in Pittsburgh on Friday.
-About to go to an Ethiopian restaurant. w00t w00t
Update:
We are now back from Canada and pictures will be posted soon.
-Currently chilling in Montreal.
-Be be back in Pittsburgh on Friday.
-About to go to an Ethiopian restaurant. w00t w00t
Update:
We are now back from Canada and pictures will be posted soon.
Thursday, March 09, 2006
kiss my axe -> mont tremblant -> super unsupervised superpixel clustering

I've been recently listening to Al Di Meola's album Kiss My Axe rather frequently. I just can't get enought of the 2nd track, titled "The Embrace."
On another note, tomorrow morning spring break starts. Me (Tomasz), Mark, Geoff, and Boris are driving to Canada to do some intense boarding and skiing at Mont Tremblant. Unfortunately, Hanns had to stay behind and do some research-related work. After hitting up the mountain, we are going to check out Montreal for a few days. In addition, on the way up we are going to stop in the Albany/Troy region for Friday night to party and relax.
Even though I'm not planning on bringing my laptop, 15 CPUs are crunching away at images of animals; I think my job should be done in about 4 days. I'm trying to do a study of segmentation algorithms so that I can implement some of the new discriminative superpixel-based recognition theory I've been working on when I get back from spring break. I'm performing the study on the {PASCAL 2006,MSRCv2,Weizmann Horse} databases and I am utilizing Stella Yu's Constrained Normalized Cuts implementation on top of Berkeley's Probability of Boundary detector. With such large collections of images, I'm going to try out some super unsupervised superpixel clustering strategies in not too long.
Wednesday, March 08, 2006
metaphysics strikes again and the console ninja
As I'm finishing up my console ninja* related work, I'm thinking about {metaphysics, undirected graphical models, Markov Chain Monte Carlo, superpixels, etc}.

*console ninja - a term I found on the internet (the person who used it was named pytholyx but I have no clue who they are) referring to somebody extremely proficient at the *nix console. It refers to one who is one with the console and can utilize the shell in a way similar to a ninja using a sword.

*console ninja - a term I found on the internet (the person who used it was named pytholyx but I have no clue who they are) referring to somebody extremely proficient at the *nix console. It refers to one who is one with the console and can utilize the shell in a way similar to a ninja using a sword.
Saturday, March 04, 2006
under pressure -> screen is my favourite *nix program
80's nite on Thursdays at the Upstage is awesome! It's a great way for people to relax after a stressfull week of graduate school and meet some other cool people. Also, where else can you expect to hear Michael Jackson's Billy Jean with a very high probability?
So today I learned that it is in fact David Bowie who sings "Under Pressure" -- a song which is generally preceded by Vanillla Ice's "Ice Ice Baby." What a great combination!
-----------------------------------------
-----------------------------------------
-----------------------------------------
Up until yesterday, SSH was my favourite *nix utility while screen was 2nd on the list. However, after a power screen-learning session yesterday I discovered the power of .screenrc files and screen rapidly jumpted to the #1 spot. In reality, there is no reason to use screen independently of SSH; however, all the fun features of screen make it just plain old awesome.
I wrote a short script that runs like:
$ screen -L -c ~/private/.screenrc
And does the following:
1.) Start 14 screen virtual terminals, and in the N-th virtual terminal do the following: ssh into a machine called "somethingN.cs.cmu.edu" and start MATLAB to start a process called "fun_batch"
2.) -L enables logging, and I have each log file name point to a web-readable directory so I can check out the output of each virtual terminal remotely
3.) Start a 15th screen virtual terminal which gives me a blank SHELL in which I can check the CPU states of the other 14 machines
Then I simply detach the screen session, and periodically check up on each MATLAB process.
Now I have to find out how to avoid using up 14 MATLAB Image Processing Toolbox Licenses. Any advice will be appreciated.
So today I learned that it is in fact David Bowie who sings "Under Pressure" -- a song which is generally preceded by Vanillla Ice's "Ice Ice Baby." What a great combination!
-----------------------------------------
-----------------------------------------
-----------------------------------------
Up until yesterday, SSH was my favourite *nix utility while screen was 2nd on the list. However, after a power screen-learning session yesterday I discovered the power of .screenrc files and screen rapidly jumpted to the #1 spot. In reality, there is no reason to use screen independently of SSH; however, all the fun features of screen make it just plain old awesome.
I wrote a short script that runs like:
$ screen -L -c ~/private/.screenrc
And does the following:
1.) Start 14 screen virtual terminals, and in the N-th virtual terminal do the following: ssh into a machine called "somethingN.cs.cmu.edu" and start MATLAB to start a process called "fun_batch"
2.) -L enables logging, and I have each log file name point to a web-readable directory so I can check out the output of each virtual terminal remotely
3.) Start a 15th screen virtual terminal which gives me a blank SHELL in which I can check the CPU states of the other 14 machines
Then I simply detach the screen session, and periodically check up on each MATLAB process.
Now I have to find out how to avoid using up 14 MATLAB Image Processing Toolbox Licenses. Any advice will be appreciated.
Wednesday, March 01, 2006
controlling a robotic system via search
Two ways of doing controls. The electrical engineering kind of way and the artificial intelligence kind of way. I like to search, and I'll go with the artificial intelligence approach anyday.
Here are the links to the last three Kinematics Dynamics & Control Homeworks:
3.)Modeling a Robotic Finger via Uniform Grid Search

2.)Optimizing the Control of a Two-Link Pendulum
1.)Controlling a Robotic Pendulum via Dijskstra-Like Backward Value Iteration

Here are the links to the last three Kinematics Dynamics & Control Homeworks:
3.)Modeling a Robotic Finger via Uniform Grid Search

2.)Optimizing the Control of a Two-Link Pendulum
1.)Controlling a Robotic Pendulum via Dijskstra-Like Backward Value Iteration

Tuesday, February 28, 2006
some statistics terminology fun
In my Statistical Learning Theory class, the professor made a funny anecdote about the difference in terminology between the fields of computer science and statistics. The point of Larry Wasserman's short discussion was to mention that the term 'inference' means two slightly different things for those two fields. The funny part of the discussion was when John Lafferty told us about a talk he attended a few years ago. During this talk, the speaker also talked about the differences in terminology between those two fields. The speaker talked about the term 'data-mining' which is often used in computer science. The analogous term in statistics is 'over-fitting.' This should make you laugh because CS people view 'data-mining' as too much of a bad thing and statisticians view 'over-fitting' as too much of a bad thing.
Wednesday, February 22, 2006
i'm not your ordinary sheep: PASCAL averages torralba-style
What do you get when you average 251 images containing sheep?

What do you get when you average 421 bounding boxes of manually segmented sheep?
I averaged scenes (Torralba-style) containing objects of interest and the bounding boxes of objects of interest from the PASCAL 2006 Challenge (see the blog entry below). You can see the results here:

What do you get when you average 421 bounding boxes of manually segmented sheep?

I averaged scenes (Torralba-style) containing objects of interest and the bounding boxes of objects of interest from the PASCAL 2006 Challenge (see the blog entry below). You can see the results here:
Means for PASCAL Visual Object Classes Challenge 2006: Dataset trainval
Monday, February 20, 2006
thinking about kats
In what follows, I shall explain why I've been recently thinking about cats. It all started last night when my friend thought he saw a paper on my desk titled "Graph Partition by Swendsen-Wang Cats." Of course what he really saw was the paper called "Graph Partition by Swendsen-Wang Cuts." However, as he laughingly mentioned that he though I was reading on spectral graph partitioning using cats (those fuzzy cute animals), my mind rapidly explored the consequences of utilizing animals such as cats for solving difficult computational problems.
How can one use cats to solve computationally intractable problems?
Consider the problem of object recognition. The goal is to take an image, perform some low-level image manipulation and present the image to a cat. Then utilizing a system that tracks the cat's physical behavior, one needs to only map the cat's response of the visual stimulus presented into a new signal -- a solution to the more difficult problem. The hypothesis underlying the Swendsen-Want Cat Theory is that one can exploit the underlying high-level intelligence of primitive life forms to solve problems that are of interest to humans.
Thus I've been thinking about kats all of last night. I guess the word 'thinking' doesn't even do justice in this context. If anybody is interested in other (perhaps even more credible) applications of cats, I can tell them about dynamic obstacle-avoiding path planning via cats or about space exploration via colonies of ants.
How can one use cats to solve computationally intractable problems?
Consider the problem of object recognition. The goal is to take an image, perform some low-level image manipulation and present the image to a cat. Then utilizing a system that tracks the cat's physical behavior, one needs to only map the cat's response of the visual stimulus presented into a new signal -- a solution to the more difficult problem. The hypothesis underlying the Swendsen-Want Cat Theory is that one can exploit the underlying high-level intelligence of primitive life forms to solve problems that are of interest to humans.
Thus I've been thinking about kats all of last night. I guess the word 'thinking' doesn't even do justice in this context. If anybody is interested in other (perhaps even more credible) applications of cats, I can tell them about dynamic obstacle-avoiding path planning via cats or about space exploration via colonies of ants.
Saturday, February 18, 2006
PASCAL Visual Object Classes Recognition Challenge 2006
The goal of this challenge is to recognize objects from a number of visual object classes in realistic scenes (i.e. not pre-segmented objects). It is fundamentally a supervised learning learning problem in that a training set of labelled images is provided.
Detailed Information and Development kit at:
http://www.pascal-network.org/challenges/VOC/voc2006/index.html
<><><><><><><><><><><><><><><><><><><><><><><><>
TIMETABLE
* 14 Feb 2006 : Development kit (training and validation data plus
evaluation software) made available.
* 31 March 2006: Test set made available
* 21 April 2006: DEADLINE for submission of results
* 7 May 2006: Half-day (afternoon) challenge workshop to be held in
conjunction with ECCV06, Graz, Austria
<><><><><><><><><><><><><><><><><><><><><><><><>
Anybody down?
It's not like going to class is going to be more fun. :D
Detailed Information and Development kit at:
http://www.pascal-network.org/challenges/VOC/voc2006/index.html
<><><><><><><><><><><><><><><><><><><><><><><><>
TIMETABLE
* 14 Feb 2006 : Development kit (training and validation data plus
evaluation software) made available.
* 31 March 2006: Test set made available
* 21 April 2006: DEADLINE for submission of results
* 7 May 2006: Half-day (afternoon) challenge workshop to be held in
conjunction with ECCV06, Graz, Austria
<><><><><><><><><><><><><><><><><><><><><><><><>
Anybody down?
It's not like going to class is going to be more fun. :D
Monday, February 13, 2006
Keep Your Friends Close and Your Markov Blankets Closer
Let me begin by explaining the Markov Property and the concept of a Markov Blanket. In probability theory, a stochastic process that has the Markov Property behaves in such a way that the future state only depends on the current state. In other words, the future state is conditionally independent of the past given the current state.
Extending the notion of a one-dimensional path of states to a higher order network of states, a Markov Blanket of a node is its set of neighbouring states. In a Bayesian network, the Markov Blanket consists of the node's parents, the node's children, and the node's children's parents.

Quoting Wikipedia, "The Markov blanket of a node is interesting because it identifies all the variables that shield off the node of the rest of the network. This means that the Markov blanket of a node is the only knowledge that is needed to predict the behaviour of that node."
I've been recently exposed to the world of Dynamic Programming for my Kinematics, Dynamics, and Control class -- taught by Chris Atkeson. For the first two assignments, I've tried to implement a Dijkstra-like Dynamic Programming algorithm for the optimal control of a robotic arm. I will not get into the technical details here, but the basic idea is to cleverly maintain the Markov Blanket of a set of alive nodes instead of performing full sweeps of configuration space when doing value iteration. It ends up that you really cannot look at neighbors in a regular grid of quantized configurations; one must model the dynamics of the problem at hand. If anybody cares for a more detailed explanation, visit my KDC hw2 page.
Why am I -- a vision hacker -- talking about optimal control of a robotic arm? Why should I care about direct policy search, value iteration, dynamic programming, and planning in high-dimensional configuration spaces. Vision is my main area of research, but I am a roboticist and this is what I do. One day robots are going to need to act in order to understand the world around them (or act because they understand the world around them), and I'm not going to simply pass my vision system over to some planning/control people so they can integrate it into their robotic system.
Extending the notion of a one-dimensional path of states to a higher order network of states, a Markov Blanket of a node is its set of neighbouring states. In a Bayesian network, the Markov Blanket consists of the node's parents, the node's children, and the node's children's parents.
Quoting Wikipedia, "The Markov blanket of a node is interesting because it identifies all the variables that shield off the node of the rest of the network. This means that the Markov blanket of a node is the only knowledge that is needed to predict the behaviour of that node."
I've been recently exposed to the world of Dynamic Programming for my Kinematics, Dynamics, and Control class -- taught by Chris Atkeson. For the first two assignments, I've tried to implement a Dijkstra-like Dynamic Programming algorithm for the optimal control of a robotic arm. I will not get into the technical details here, but the basic idea is to cleverly maintain the Markov Blanket of a set of alive nodes instead of performing full sweeps of configuration space when doing value iteration. It ends up that you really cannot look at neighbors in a regular grid of quantized configurations; one must model the dynamics of the problem at hand. If anybody cares for a more detailed explanation, visit my KDC hw2 page.
Why am I -- a vision hacker -- talking about optimal control of a robotic arm? Why should I care about direct policy search, value iteration, dynamic programming, and planning in high-dimensional configuration spaces. Vision is my main area of research, but I am a roboticist and this is what I do. One day robots are going to need to act in order to understand the world around them (or act because they understand the world around them), and I'm not going to simply pass my vision system over to some planning/control people so they can integrate it into their robotic system.
Friday, February 10, 2006
physical strength = mental health
In 11th grade of high school, I was at the peak of my physical strength. My one-rep max was 225 lbs on the benchpress and I weighed 165 pounds. After a few stressful years of college filled with quantum mechanics and 3D laser data analysis, I've decided to start a semi-strict weight lifting schedule when I moved to Pittsburgh. I've been lifting weights and running on a steady basis since August and I feel great!
I'm at 172 lbs now, and almost at the 225lb bench max level. Yesterday I had a good lift and was able to get 205 lbs up 4 times. This means that in just 2 weeks I should be back to my 225lb max level! w00t! My goal is to get 240lbs up 1nce before the summer season starts, but if that doesn't happen then I'd like to be able to at least finish each chest workout with a few reps of 225lbs. I've realized that the key to moving up in weight on the benchpress is making sure that all those little muscles that you use in the chest/shoulder/tricep area get hit pretty hard every once in a while. You are only as strong as your weakest link.
I can't wait until warm weather so I can start running in the mornings. (I also might give yoga a shot in the spring.)
The question at the end of the day is: why bother lifting weights if you're not competing in a sport that requires physical strength? The answer is that physical well-being is intimately related to mental health, which directly influences the progress of my research in computer vision.
I'm at 172 lbs now, and almost at the 225lb bench max level. Yesterday I had a good lift and was able to get 205 lbs up 4 times. This means that in just 2 weeks I should be back to my 225lb max level! w00t! My goal is to get 240lbs up 1nce before the summer season starts, but if that doesn't happen then I'd like to be able to at least finish each chest workout with a few reps of 225lbs. I've realized that the key to moving up in weight on the benchpress is making sure that all those little muscles that you use in the chest/shoulder/tricep area get hit pretty hard every once in a while. You are only as strong as your weakest link.
I can't wait until warm weather so I can start running in the mornings. (I also might give yoga a shot in the spring.)
The question at the end of the day is: why bother lifting weights if you're not competing in a sport that requires physical strength? The answer is that physical well-being is intimately related to mental health, which directly influences the progress of my research in computer vision.
Tuesday, February 07, 2006
Tarrega Classical Guitar Tablature
Check out these two songs by Tarrega:
Here are links to the classical guitar tablature.
Etude in Em: http://www.classtab.org/ftaet_em.txt
Lagrima: http://www.classtab.org/ftalagri.txt
Here are links to the classical guitar tablature.
Etude in Em: http://www.classtab.org/ftaet_em.txt
Lagrima: http://www.classtab.org/ftalagri.txt
Wednesday, February 01, 2006
a jordan sighting, a null space, and a google robot!
A few days ago, my friend John spotted Michael Jordan in Wean Hall. I commented that John should have had Jordan draw a graphical model on a piece of paper (or just draw it on his arm with a permanent marker) and autograph it!
On another note, I saw this image in a paper called Object Categorization by Learned Universal Visual Dictionary by Winn, Criminsci, and T. Minka. This image, which depicts a rough human segmentation of an image of a cow, contains a 'null' space. In Statistical Machine Learning class, we reviewed some linear algebra and thus talked about the 'null space' associated with a linear operator.

Ever hear of google robots? Ever read 1984?
On another note, I saw this image in a paper called Object Categorization by Learned Universal Visual Dictionary by Winn, Criminsci, and T. Minka. This image, which depicts a rough human segmentation of an image of a cow, contains a 'null' space. In Statistical Machine Learning class, we reviewed some linear algebra and thus talked about the 'null space' associated with a linear operator.

Ever hear of google robots? Ever read 1984?
Sunday, January 29, 2006
Philosophy of Robotics Reading Group
A fellow roboticist, Geoff, recently started the Philosophy of Robotics Reading Group and we had a great first meeting last Friday. We talked about robot emotions, and if anybody wants to see the papers that we discussed then please visit the reading group page.
I will one day present something about the current state and future of computer vision and how it relates to realist and pragmatist philosophy. In particular, I will talk about 'correspondence to reality' and how current work in computer vision poses such objective functions that are consistent with the realist paradigm. On the other side, a pragmatist view of vision would be less concerned with correspondence to anything (what is really out there?) , and more concerned with completion of a vision task.
From an evolutionary point of view, there is no reason for our internal representation to correspond to anything 'out there'; however, from an intelligent design point of view (which I do not advocate) then it would seem appropriate to create a being that can get at something out there.
I will one day present something about the current state and future of computer vision and how it relates to realist and pragmatist philosophy. In particular, I will talk about 'correspondence to reality' and how current work in computer vision poses such objective functions that are consistent with the realist paradigm. On the other side, a pragmatist view of vision would be less concerned with correspondence to anything (what is really out there?) , and more concerned with completion of a vision task.
From an evolutionary point of view, there is no reason for our internal representation to correspond to anything 'out there'; however, from an intelligent design point of view (which I do not advocate) then it would seem appropriate to create a being that can get at something out there.
Saturday, January 21, 2006
pic of my brother from winter indoctrination 2006

Can you find Matt in this picture? Well, you might not be able to, but I surely can.
Wednesday, January 18, 2006
human retinal system
Today in class (advanced perception), we talked about the human retinal system and the various nerve cells that the signal passes through. It appears that there are many nervous arrangements that pick up 'corners.' The reason why this is important is that these corners are very discriminative; humans can recognize many things from line drawings.

You could imagine a Martian who wants to study the human brain. An analysis of the human retinal system would reveal that we are geared for life on earth (certain arrangements in the retinal system respond to certain visual structures), and the Martian could obtain invaluable details about the world on Earth by studying the human's brain. Of course, the Martian would not know what a particular human saw, he would see what humans as a species (a point in some infinite dimensional space that evolution is traversing) are tuned in to see. He would probably have some knowledge of the distribution of spatial objects that we -- humans -- normally see and have some idea of the density of objects in the human-scale visual world on Earth.
On another note, I googled the term "human retinal system matched filter" and found a paper that was written by Michal Sofka and Charles Stewart about extracting vasculature using a set of matched filters; and even though I meant to find a web page which talked about how certain structures in the eye are tuned in to respond to certina visual stimuli, I found a paper on a different topic which nevertheless mentions my name in the acknowledgements section! (They were using some of the generalized vesel tracing implementation I wrote while researching at RPI.)
You could imagine a Martian who wants to study the human brain. An analysis of the human retinal system would reveal that we are geared for life on earth (certain arrangements in the retinal system respond to certain visual structures), and the Martian could obtain invaluable details about the world on Earth by studying the human's brain. Of course, the Martian would not know what a particular human saw, he would see what humans as a species (a point in some infinite dimensional space that evolution is traversing) are tuned in to see. He would probably have some knowledge of the distribution of spatial objects that we -- humans -- normally see and have some idea of the density of objects in the human-scale visual world on Earth.
On another note, I googled the term "human retinal system matched filter" and found a paper that was written by Michal Sofka and Charles Stewart about extracting vasculature using a set of matched filters; and even though I meant to find a web page which talked about how certain structures in the eye are tuned in to respond to certina visual stimuli, I found a paper on a different topic which nevertheless mentions my name in the acknowledgements section! (They were using some of the generalized vesel tracing implementation I wrote while researching at RPI.)
Monday, January 16, 2006
compression as understanding
compression:
Instead of thinking of compression as something that is used to reduce the size of data, consider it as a measure of understanding data that generalizes well to unseen data. One should view compression as understanding.
Imagine that you walk to class using your normal route while listening to your ipod. Even though you were aware of your surroundings while walking, it was most likely an indirect experience where you remember only subtle little details related to the walk. However, you can still be 100% sure that you had taken the same path as last time. While you were walking, your brain 'understood' the environment dynamically and it only needed a low bit stream (dynamically compressed) of visual information to localize you. This of this notion of compression as model fitting, where the objects of perception are the model parameters and the raw data is inaccesible.
Even though your experience of walking lasted 20 minutes, you feel like you didn't acquire much experience as opposed to spending 20 minutes in a completely new place. Your brain selectively took in information; you might have remembered seeing somebody you recognize drive by but forgot some of the songs that you listened to.
The notion of "an object recognition system" using a "segmentation algorithm" is the traditional definition of segmentation as a mid-level process and object recognition as a high-level process. However, you can't really segment until you've recognized. Recognition and segmentation should be viewed on an equal footing; unified.
Instead of thinking of compression as something that is used to reduce the size of data, consider it as a measure of understanding data that generalizes well to unseen data. One should view compression as understanding.
Imagine that you walk to class using your normal route while listening to your ipod. Even though you were aware of your surroundings while walking, it was most likely an indirect experience where you remember only subtle little details related to the walk. However, you can still be 100% sure that you had taken the same path as last time. While you were walking, your brain 'understood' the environment dynamically and it only needed a low bit stream (dynamically compressed) of visual information to localize you. This of this notion of compression as model fitting, where the objects of perception are the model parameters and the raw data is inaccesible.
Even though your experience of walking lasted 20 minutes, you feel like you didn't acquire much experience as opposed to spending 20 minutes in a completely new place. Your brain selectively took in information; you might have remembered seeing somebody you recognize drive by but forgot some of the songs that you listened to.
The notion of "an object recognition system" using a "segmentation algorithm" is the traditional definition of segmentation as a mid-level process and object recognition as a high-level process. However, you can't really segment until you've recognized. Recognition and segmentation should be viewed on an equal footing; unified.
metaphysics: looking through a window of unsupervision
The role of metaphysics in the field of computer vision cannot be forgotten. Today I sat in my first class of the Spring 2006 semester. I'm very excited about this course, titled Advanced Robot Perception (or Advanced Machine Perception, but everybody calls it Advanced Perception anyways) which is being taught by my research advisor, Alexei Efros.
While sitting in class and listening to Alexei talk, I remembered my first day of 11th-grad high school honors english. On that first day of english class, the teacher had placed a quote on the blackboard which said, "The window through which we peer circumscribes the world we see." In some sense, this quotation represents my internal philosophy wery well. As a pragmatist -- one who's scientific outlook on life has been shaped by philosophies of Kuhn, Popper, and Rorty -- I hold on to a somewhat wishy-washy concept of truth. Perhaps I started reading Descartes when I was a bit too young, but I'm simply a sucker for Cartesian hyberbolic doubt. Perhaps I don't agree with the common man's world-view, perhaps I doubt the existence of the world outside of my head, perhaps I'm simply not willing to tell my vision system what the world is made up of.
My fascination with unsupervised techniques in computer vision is directly related to my pragmatic philosophy. Perhaps there is nothing wrong with using the objects that we have words for when we (humans) communicate, but I'm just skeptical of the fact that these high-level objects are the objects that we directly perceive. If we want to ask a vision system something about the visual world using natural language, then the vision system will clearly have to translate the english-word concept to its own internal representation of the objects it sees. However, if we want to build vision systems that can interact with the world on their own and there is no need to directly 'talk to the machines' using natural language, then why should we impose an internal structure on their internal representation. Why should we impose a 1:1 correspondence between the objects of language and the objects of perception?
Clearly, a hierarchical representation of objects is necessary since a linear structure simply does not scale to the large number of objects present in the world. I'm currently thinking about image-level primitives that could be used to construct such a hierarchical representation.
Wikipedia says it nicely, "A major concern of metaphysics is a study of the thought process itself: how we perceive, how we reason, how we communicate, how we speculate, and so on." I want to build robotic metaphysicians so that I can ask them 'what is the meaning of life?' Even though I know that the answer will be 42, I think it will be a fun journey.
While sitting in class and listening to Alexei talk, I remembered my first day of 11th-grad high school honors english. On that first day of english class, the teacher had placed a quote on the blackboard which said, "The window through which we peer circumscribes the world we see." In some sense, this quotation represents my internal philosophy wery well. As a pragmatist -- one who's scientific outlook on life has been shaped by philosophies of Kuhn, Popper, and Rorty -- I hold on to a somewhat wishy-washy concept of truth. Perhaps I started reading Descartes when I was a bit too young, but I'm simply a sucker for Cartesian hyberbolic doubt. Perhaps I don't agree with the common man's world-view, perhaps I doubt the existence of the world outside of my head, perhaps I'm simply not willing to tell my vision system what the world is made up of.
My fascination with unsupervised techniques in computer vision is directly related to my pragmatic philosophy. Perhaps there is nothing wrong with using the objects that we have words for when we (humans) communicate, but I'm just skeptical of the fact that these high-level objects are the objects that we directly perceive. If we want to ask a vision system something about the visual world using natural language, then the vision system will clearly have to translate the english-word concept to its own internal representation of the objects it sees. However, if we want to build vision systems that can interact with the world on their own and there is no need to directly 'talk to the machines' using natural language, then why should we impose an internal structure on their internal representation. Why should we impose a 1:1 correspondence between the objects of language and the objects of perception?
Clearly, a hierarchical representation of objects is necessary since a linear structure simply does not scale to the large number of objects present in the world. I'm currently thinking about image-level primitives that could be used to construct such a hierarchical representation.
Wikipedia says it nicely, "A major concern of metaphysics is a study of the thought process itself: how we perceive, how we reason, how we communicate, how we speculate, and so on." I want to build robotic metaphysicians so that I can ask them 'what is the meaning of life?' Even though I know that the answer will be 42, I think it will be a fun journey.
Sunday, January 15, 2006
transcending scale and gravity learning
A machine which has primitive 'in-the-moment' direct perception of the world is one that solved the small spatio-temporal scale correspondence problem. Here, the time dimension is represented with a time-ordered sequence of images, and spatial scale refers to the distance between objects (in 3-space and/or in image-space). Being able to group together similar pixels and performing a mid-level segmentation of 1 image is the single image segmentation problem. One could imagine using a small temporal scale that corresponds to a negligible view-point variation, and registering the superpixels in that sequence. However, the ability to register superpixels across small temporal scale, aka direct perception, doesn't solve the problem of vision in its entirety.
The ability to transcend spatio-temporal scale and register objects across all of time as opposed to a small temporal window is necessary in order to have true image understanding. You can think of direct perception as the process of staring at something and not thinking about anything but the image that you see. In some sense, direct perception is not even possible for humans. However, indirect perception is the key to vision. Imagine sitting on your couch and typing on your laptop, while staring at the laptop screen. If you're in a familiar location, then you don't have to really look around too much since you know how everything is arranged; in some sense you have such a high prior on what you expect to see, that you need minimal image data (only what you see on the fringes of your vision as you stare at the monitor) to understand the world around you. Or imagine walking down a street and closing your eyes for two seconds; you can almost 'see' the world around you, yet your eyes are closed. These examples show that there is a model of the world inside of us that we can be directly aware of even when our eyes are closed. I would be willing to bet that after training on high quality image data, a real-time system would be able to understand the world with an extremely low-quality camera.
On another note, I would like to build computer vision systems that can infer fundamental physical relationships relating to observed objects such as the law of gravity. Such physical relations will come out if they help 'compress' image data; and they always do. The reason why the concept of gravity compresses image data is that it places a strong prior on the relative locations of familiar objects. For example, the conditional probability density function over the rigid-body configuration of a vehicle given the configuration of a road is significantly lower dimensional than the marginal probability density of the vehicle configuration. In lamens terms, if you know where a road is in an image then you can be pretty sure where you are going to find the cars in the image and if you don't know the location of the road then the cars could be located anywhere in the image plane. If we want intelligent agents to see the physical world around them, we have to remember that they will only be able to understand the large amount of visual data that we give them if they can compress it. In this context, compressing image data is equivalent to performing object recognition on the image. Compression will not only occur at the object-level, but also at the world-level. Object-level compression entails understanding hierarchies of objects (such as a ford is a car) while world-level compression entails understanding the physical relationships between objects in the world. Object-level compression is important if we want to understand all of the different objects in the world, and world-level compression is necessary if we ever want to 'understand' it in a reasonable amount of time. Object-level compression is also related to the concept of meta-objects and the question of object generalization. World-level compression is related to physics and metaphysics.
The ability to transcend spatio-temporal scale and register objects across all of time as opposed to a small temporal window is necessary in order to have true image understanding. You can think of direct perception as the process of staring at something and not thinking about anything but the image that you see. In some sense, direct perception is not even possible for humans. However, indirect perception is the key to vision. Imagine sitting on your couch and typing on your laptop, while staring at the laptop screen. If you're in a familiar location, then you don't have to really look around too much since you know how everything is arranged; in some sense you have such a high prior on what you expect to see, that you need minimal image data (only what you see on the fringes of your vision as you stare at the monitor) to understand the world around you. Or imagine walking down a street and closing your eyes for two seconds; you can almost 'see' the world around you, yet your eyes are closed. These examples show that there is a model of the world inside of us that we can be directly aware of even when our eyes are closed. I would be willing to bet that after training on high quality image data, a real-time system would be able to understand the world with an extremely low-quality camera.
On another note, I would like to build computer vision systems that can infer fundamental physical relationships relating to observed objects such as the law of gravity. Such physical relations will come out if they help 'compress' image data; and they always do. The reason why the concept of gravity compresses image data is that it places a strong prior on the relative locations of familiar objects. For example, the conditional probability density function over the rigid-body configuration of a vehicle given the configuration of a road is significantly lower dimensional than the marginal probability density of the vehicle configuration. In lamens terms, if you know where a road is in an image then you can be pretty sure where you are going to find the cars in the image and if you don't know the location of the road then the cars could be located anywhere in the image plane. If we want intelligent agents to see the physical world around them, we have to remember that they will only be able to understand the large amount of visual data that we give them if they can compress it. In this context, compressing image data is equivalent to performing object recognition on the image. Compression will not only occur at the object-level, but also at the world-level. Object-level compression entails understanding hierarchies of objects (such as a ford is a car) while world-level compression entails understanding the physical relationships between objects in the world. Object-level compression is important if we want to understand all of the different objects in the world, and world-level compression is necessary if we ever want to 'understand' it in a reasonable amount of time. Object-level compression is also related to the concept of meta-objects and the question of object generalization. World-level compression is related to physics and metaphysics.
Thursday, January 12, 2006
recognition as segmentation across time
Let me start out my brief discussion with a segmentation result:

This is the image the New Year's Party picture that I posted a few posts ago. This is the result of Felzenszwalb's graph based segmentation executable. I ran the executable many times by uniformly sampling the input parameter space and selected one image which looked particularly nice.
Segmentation is generally referred as a mid-level process, ie a process which groups together similar regions. However, it is still not a high-level process because it doesn't use any information from other images. When the concept of segmentation was introduced into the vision community, researchers thought that it would a good pre-processing step that would further aid object recognition. However, the community quickly realized that an object-consistent segmentation is only possible after the objects have been identified in the image!
Image segmentation is still very popular as of 2006; however, the traditional definition of segmentation as something you do before recognition is slowly becoming outdated. Modern research on segmentation has a significant object-recognition feel to it, and one interesting question that remains is: how does one incorporate information from a large set of images to segment 1 image?
Every problem in computer vision can be solved with an object recognition module, unfortunately recognition is the most difficult. Computer vision is not simply image processing. Computer vision strives to build machines that can make synthetic a posteriori statements about the world. If Emmanuel Kant was alive this day, he would be a vision hacker.

This is the image the New Year's Party picture that I posted a few posts ago. This is the result of Felzenszwalb's graph based segmentation executable. I ran the executable many times by uniformly sampling the input parameter space and selected one image which looked particularly nice.
Segmentation is generally referred as a mid-level process, ie a process which groups together similar regions. However, it is still not a high-level process because it doesn't use any information from other images. When the concept of segmentation was introduced into the vision community, researchers thought that it would a good pre-processing step that would further aid object recognition. However, the community quickly realized that an object-consistent segmentation is only possible after the objects have been identified in the image!
Image segmentation is still very popular as of 2006; however, the traditional definition of segmentation as something you do before recognition is slowly becoming outdated. Modern research on segmentation has a significant object-recognition feel to it, and one interesting question that remains is: how does one incorporate information from a large set of images to segment 1 image?
Every problem in computer vision can be solved with an object recognition module, unfortunately recognition is the most difficult. Computer vision is not simply image processing. Computer vision strives to build machines that can make synthetic a posteriori statements about the world. If Emmanuel Kant was alive this day, he would be a vision hacker.
Wednesday, January 11, 2006
we, the lunatics, and the two Smiths
I would like to briefly comment on the dystopia presented in Orwell's 1984 and its relationship to Heinlein's utopia from Stranger in a Strange Land. Winston Smith's world -- the world of 1984 -- is a world where the Party has determined how man should live his or her life. In this cold and lonesome world, man has been taught to suppress his or her emotions/instincts/desires, cast doubt on their senses, and love their patron -- Big Brother. Characteristic of this dystopia is the mechanical progression of every man's daily life; the irrational and unpredictable elements of modern human life have deemed as crimes. It is important to note that the world of 1984, as presented in the first half of the book, is the dystopia while the hypothetical world of hope and freedom that exists in Winston's mind is the utopia. Orwell presents a world where many people are aware of some shadow lurking in the background -- something wrong with the current way of life -- but they are simply too weak to do anything about it on their own.
The world of Michael Valentine Smith -- the Man from Mars -- is so magical that is transcends the word utopia. By introducing elements from science fiction, Heilnein carefully presents the reader with a world of unfettered emotion, a world introduced to humanity by the man from Mars. In Stranger from a Strange Land, the utopian state is induced by Smith's way of life and embodied by the inhabitants of the Nest (read the book to find out more about this). This utopia (by introducing elements from fiction, Heinlein makes this an extravagantly exaggerated utopia) can be compared to the human way of life the way it was before Michael Valentine Smith arrived. All that is prohibited in the world of Big Brother is encouraged in the world of Michael Valentine Smith. By presenting such a utopian way of life, perhaps Heinlein wanted us to focus on the world the way it was before it was touched by Michael Valentine Smith. Although Heinlein portrays the future as very similar to the modern world as of 2006, it nevertheless portrays it as a sort of dystopia. The big difference between the world of Stranger in a Strange Land (before the Man from Mars came) and the world of 1984 is that Oceania's denizens are somewhat aware of their predicament while the citizens of Heinlein's world only become aware of their situation after their savior comes.
Just how different is the world of 2006 compared to the world of 1984? Does one have to be aware of their predicament for the predicament to truly exist?
The world of Michael Valentine Smith -- the Man from Mars -- is so magical that is transcends the word utopia. By introducing elements from science fiction, Heilnein carefully presents the reader with a world of unfettered emotion, a world introduced to humanity by the man from Mars. In Stranger from a Strange Land, the utopian state is induced by Smith's way of life and embodied by the inhabitants of the Nest (read the book to find out more about this). This utopia (by introducing elements from fiction, Heinlein makes this an extravagantly exaggerated utopia) can be compared to the human way of life the way it was before Michael Valentine Smith arrived. All that is prohibited in the world of Big Brother is encouraged in the world of Michael Valentine Smith. By presenting such a utopian way of life, perhaps Heinlein wanted us to focus on the world the way it was before it was touched by Michael Valentine Smith. Although Heinlein portrays the future as very similar to the modern world as of 2006, it nevertheless portrays it as a sort of dystopia. The big difference between the world of Stranger in a Strange Land (before the Man from Mars came) and the world of 1984 is that Oceania's denizens are somewhat aware of their predicament while the citizens of Heinlein's world only become aware of their situation after their savior comes.
Just how different is the world of 2006 compared to the world of 1984? Does one have to be aware of their predicament for the predicament to truly exist?
Monday, January 09, 2006
back in style
I'm back in Pittsburgh, reading 1984, arpeggiating 7th cords, and getting ready for classes to start.
Thursday, January 05, 2006
four books and a drive with the new deal
I recently finished Stranger In a Strange Land and I will be leaving Long Island with four new books tomorrow. I have recently purchased Tom Wolfe's I Am Charlotte Simmons, Neal Stephenson's Quicksilver, George Orwell's Nineteen Eighty-Four, and I acquired Dune by Frank Herbert as a gift. I'm not sure what to read next, but I'll gladly take any recommendations.
I will be driving from Long Island to Pittsburgh tomorrow after I drop off my brother at Maritime College. Today I downloaded The New Deal's New Year's show at B.B. King's and I look forward to listening to that on the way. I should be blogging from Shadyside shortly.
I will be driving from Long Island to Pittsburgh tomorrow after I drop off my brother at Maritime College. Today I downloaded The New Deal's New Year's show at B.B. King's and I look forward to listening to that on the way. I should be blogging from Shadyside shortly.
Tuesday, January 03, 2006
Stranger: done!
Stranger In a Strange Land by Robert A. Heinlein isn't your stereotypical science fiction novel. It is a novel that leaves the reader thinking about love, their own life, and ethics; therefore, I would only recommend it for the philosophically inclined.
Although under the most straightforward interpretation of the title there is nothing ambiguous about the words 'stranger' and 'strange', there is an alternate interpretation that I would like to proffer. Under the straightforward interpretation, the stranger is Valentine Michael Smith -- the man from Mars -- and the strange land is earth.
Alternatively, one can interpret the word 'stranger' in the title of this novel to relate to any human living on earth who is not accustomed to the Martian way of life, an unenlightened individual. The 'strange land' would then refer to the very same Earth -- a very strange place for the unenlightened human. Under this interpretation, I am using the "One who is unaccustomed to or unacquainted with something specified; a novice." definition of 'stranger' and the "Not previously known; unfamiliar." definition of 'strange'. These definitions were taken from the 'stranger' entry on dictionary.com.
This novel does a good job at showing how non-Martian lifestyle-following, earth-dwelling humans are novices in the game of life. The stranger is the human who has grown old and weary in his ways by adhering to the tenets of modern society. The novel shows how such a non-Martian lifestyle leaves one unfamiliar with respect to the taste of reality. The man from Mars handed out a taste of Utopia and the strangers were the humans who haven't yet shared water and grown closer. Perhaps Heinlein wanted to convey the idea that the strangeness of the world around us is intimately related to our world view; Mike wanted to make the world less strange for the denizens of Earth.
Ahead of its time (this book was released in the early 60s and not the early 70s) and promoting a pantheistic view that emphasizes personal responsibility in our own lives, this book is not only entertaining but it will leave the reading asking questions.
Although under the most straightforward interpretation of the title there is nothing ambiguous about the words 'stranger' and 'strange', there is an alternate interpretation that I would like to proffer. Under the straightforward interpretation, the stranger is Valentine Michael Smith -- the man from Mars -- and the strange land is earth.
Alternatively, one can interpret the word 'stranger' in the title of this novel to relate to any human living on earth who is not accustomed to the Martian way of life, an unenlightened individual. The 'strange land' would then refer to the very same Earth -- a very strange place for the unenlightened human. Under this interpretation, I am using the "One who is unaccustomed to or unacquainted with something specified; a novice." definition of 'stranger' and the "Not previously known; unfamiliar." definition of 'strange'. These definitions were taken from the 'stranger' entry on dictionary.com.
This novel does a good job at showing how non-Martian lifestyle-following, earth-dwelling humans are novices in the game of life. The stranger is the human who has grown old and weary in his ways by adhering to the tenets of modern society. The novel shows how such a non-Martian lifestyle leaves one unfamiliar with respect to the taste of reality. The man from Mars handed out a taste of Utopia and the strangers were the humans who haven't yet shared water and grown closer. Perhaps Heinlein wanted to convey the idea that the strangeness of the world around us is intimately related to our world view; Mike wanted to make the world less strange for the denizens of Earth.
Ahead of its time (this book was released in the early 60s and not the early 70s) and promoting a pantheistic view that emphasizes personal responsibility in our own lives, this book is not only entertaining but it will leave the reading asking questions.
Experience More in 2006
I've always been troubled by the concept of a New Year's Resolution. There's nothing special about the start of a new calendar year that warrants a change in one's life. I'm not saying that people are wrong in wanting to do something such as 'exercise more' or 'quit smoking'; however, they should do those things for a reason that transcends the progression of the calendar year.
A good resolution is to Experience More. Simply put, Experiencing More translates to looking past the barriers that have been shaped around us and mandate our daily experience. Experiencing More is grokking that there is more to life than the predictable routine of daily life; it is an attempt to spice up the story of our life. The routine of modern life acts as a strong force that binds us to a particular beat of life and the first step in Experiencing More is understanding what aspects of our life are too predictable. To become a navigator of the space of all beats one has to only perturb their daily routine and be aware of the world around them as everything will take care of itself.
Aquafraternally yours,
Tomasz
A good resolution is to Experience More. Simply put, Experiencing More translates to looking past the barriers that have been shaped around us and mandate our daily experience. Experiencing More is grokking that there is more to life than the predictable routine of daily life; it is an attempt to spice up the story of our life. The routine of modern life acts as a strong force that binds us to a particular beat of life and the first step in Experiencing More is understanding what aspects of our life are too predictable. To become a navigator of the space of all beats one has to only perturb their daily routine and be aware of the world around them as everything will take care of itself.
Aquafraternally yours,
Tomasz
Monday, January 02, 2006
new years fiesta picture

Here is a picture of Cole, Dan, Me, and Roseann from the New Year's Party I attended.
Subscribe to:
Posts (Atom)