 Here are our top 9 sheep detections sorted by a primitive confidence value. The dotted green bounding box is our result and the ground truth label is in yellow. Note that our top 9 sheep detections are all true positives.
Here are our top 9 sheep detections sorted by a primitive confidence value. The dotted green bounding box is our result and the ground truth label is in yellow. Note that our top 9 sheep detections are all true positives.Monday, April 17, 2006
localizing sheep
Here are our top 9 sheep detections sorted by a primitive confidence value. The dotted green bounding box is our result and the ground truth label is in yellow. Note that our top 9 sheep detections are all true positives.Saturday, April 15, 2006
no longer waiting to hear about NDSEG fellowship...
No longer waiting to hear back about the NDSEG fellowship...(note the title changed) There's a good chance that you are reading this because you googled something like "NDSEG blog," so don't think that you haven't heard back because you simply didn't win. As of April 15th, I don't know anyone who heard back from NDSEG. Good luck all! We will find out soon enough.
As of April 28th, everybody that I know who has applied already heard back.
Update: some people heard back (positive replies!) last Friday (the Friday following April 15th)
Update++: I didn't win the NDSEG fellowship; however, I'm still quite happy with winning the NSF fellowship.
As of April 28th, everybody that I know who has applied already heard back.
Update: some people heard back (positive replies!) last Friday (the Friday following April 15th)
Update++: I didn't win the NDSEG fellowship; however, I'm still quite happy with winning the NSF fellowship.
Thursday, April 13, 2006
being bayesian about DNA: encoding hyperparameters?
During one's lifetime, one will have to learn how to accomplish many different tasks. How different are all of these learning problems? As of 2006, researchers have broken up the field of artificial intelligence into subfields which study particular learning problems such as: vision, path planning, and manipulation. These are all examples of tasks at which human excel without any hardship. Should researchers be studying these problems independently? One can imagine that the human's intellect consists of many modules which are responsible for learning how to do all of the magnificent things that we do. One can proceed to be Bayesian about this learning architecture and somehow relate these learning modules hierarchically via some type of prior. Perhaps researchers should be studying Machine Learning architectures that allow a system to rapidly learn how to solve novel problems once it has solved other (similar?) problems.
Throughout one's life, the learning modules will be at work and over time reach some 'state.' (One can think of this 'state' as an assignment of values to some nodes in a Bayesian Hierarchical Model). However, this state is a function of one's experiences and isn't anything that can be passed on from one generation to another. We all know that one cannot pass down what they learned via reproduction. Then what are we passing down from one generation to another?
The reason why the state of a human's brain cannot be passed down is that it simply won't compress down into anything small enough that can fit inside of a cell. However, the parameters of the prior associated with all of these learning problems [that a person solves throughout their life] is a significantly smaller quantity that can be compressed down to the level of a cell. One can view DNA as a capsule that contains these hyperparameters. Once passed down from one generation to another, these parameters would determine how likely one is going to be; however, the state of the new brain will have be filled in again from experience in the real world.
Since evolution is governed by a high level of stochasticity then one can view nature as performing a gradient-free search through the space of all hyperparameters. How does nature evaluate the performance of a given hyperparameter value? Well, each human (an instantiation of those hyperparamters) works up to a 'state' and his/her survival/reproduction contribute to the score of that hyperparameter setting.
Throughout one's life, the learning modules will be at work and over time reach some 'state.' (One can think of this 'state' as an assignment of values to some nodes in a Bayesian Hierarchical Model). However, this state is a function of one's experiences and isn't anything that can be passed on from one generation to another. We all know that one cannot pass down what they learned via reproduction. Then what are we passing down from one generation to another?
The reason why the state of a human's brain cannot be passed down is that it simply won't compress down into anything small enough that can fit inside of a cell. However, the parameters of the prior associated with all of these learning problems [that a person solves throughout their life] is a significantly smaller quantity that can be compressed down to the level of a cell. One can view DNA as a capsule that contains these hyperparameters. Once passed down from one generation to another, these parameters would determine how likely one is going to be; however, the state of the new brain will have be filled in again from experience in the real world.
Since evolution is governed by a high level of stochasticity then one can view nature as performing a gradient-free search through the space of all hyperparameters. How does nature evaluate the performance of a given hyperparameter value? Well, each human (an instantiation of those hyperparamters) works up to a 'state' and his/her survival/reproduction contribute to the score of that hyperparameter setting.
Tuesday, April 11, 2006
cow and the new warmth
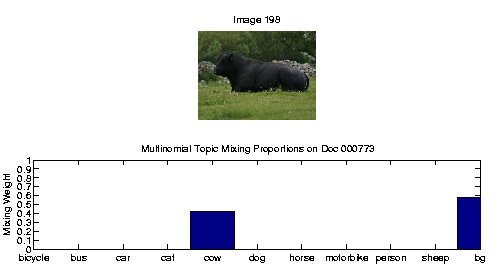
The above bar graph displays the topic mixing proportions for the image above. Clearly, the cow has been detected in an image classification sense (contains cow or not); however, we still have to see how well we are localizing the cow.
On another note, the weather has started getting nicer in Pittsburgh. I really miss late night walks around Shadyside when the weather in exceedingly warm. In a few days I'll know how well we (Jon and I) do on the CMU-level PASCAL challenge; I need to spend more time in the local park.
Finally, I've been trying to understand why I'm good at difficult things. I guess I both like the challenge and I like to work hard; however, it's not healthy to view all of life as a sequence of challenges that one can simply overcome with hard work. It takes some thought into deciding which challenges are worthy and which ones aren't worthy of pursuit; it's even more difficult deciding which ones can and which ones cannot be overcome with hard work. Life is mysterious because it occasionally presents one with challenges that require more of 'a cool air' around you than anything close to hard work. CGA said something along these lines during class a few months ago, "If you really want something, sometimes you have to step back." In conclusion, apparant lack of motivation for accomplishing a task doesn't necessarily imply a lack of desire for obtaining that goal; sometimes stepping back should be thought of as a regrouping stage -- a period of time during which one can refine their strategy and either come back with double the momentum or find a new problem to address.
Monday, April 10, 2006

Saturday, April 08, 2006
Finding Sheep -> Pigs on the Wing?

In a latent topic model (aspect model), each document has an associated distribution over latent topics (the mixing proportions). Here, the topics of the scene are mostly composed of the grass and sheep topic.
The mixing proportions on the graph above were obtained using the variational inference procedures that Jon and I wrote for our MATLAB implementation of Latent Dirichlet Allocation.
Wednesday, April 05, 2006
segmentation is not a k-way partition of an image
I have been recently working with Jon on a latent topic model for simultaneous object detection and segmentation. We are studying the use of a certain type of Hierarchical Bayesian Model (a variant of Blei's Latent Dirichlet Allocation) with dense image features (to be described in the near future) and applying our algorithm to the 2006 PASCAL Visual Object Classes Challenge.
Since I've been introduced to DDMCMC for image segmentation, I have been thinking about the relationship between segmentation and recognition. Also, in my Advanced Perception course, we recently looked at some Borenstein/Ullman papers that incorporate segmentation and recognition into one framework (this resulted in a few more ideas). Here are some short ideas about segmentation:
How is the problem of segmentation usually posed? Given an image, produce a partition of the image into K disjoint regions. If one wants to only use the image data given with no object-level assumptions, then one can only proceed to find the maximum likelihood segmentation. However, such a segmentation will have a very large variance (and a small bias) because there are many different ways of 'grouping' local image structures together.
Fortunately, one can be Bayesian and relate the 'seemingly independent' problems of segmenting different images by utilizing a prior over image regions. When employing a Bayesian Hierarchical model, one generally breaks down the problem into two stages: parameter estimation(training) and statistical inference(testing). Just like in the LDA model, parameter estimation is concerned with estimating the hyperparameters of the hierarchical model (and also finding the distributions over latent variables for each document in the training set) and inference is segmenting a novel image (by utilizing the parameters obtained in the training stage). By being Bayesian, one will introduce bias when segmenting a novel image (the bias will make the novel segmentation more like some of the segmentations that were obtained for the training corpus) and reduce variance. Isn't bias a good thing in this case? Don't we REALLY want a novel segmentation to be somehow related to other segmentations? Perhaps the only property about a segmentation engine that we care about is its object-level consistency across a wide number of images. We hope that: given a large enough training corpus that captures large variability in pose and appearance for a large number of objects, the 'semantic'-segmentation that is desired will be the one that is approximated with our hierarchical model. A latent topic-based segmentation engine would additionaly provide a registration across image features via the latent topic space. In other words, semantically equivalent image primitives would be near each other in some high dimensional latent-topic parameter space.
The new question should be: How can we learn to segment novel images given a corpus of images that are somehow related? Under this view, a segmentation of a novel image is a k-way parition of an image AND the latent topic distributions associated with each segment (registration of segments across images). Remember, object tracking is temporal registration and object recognition is semantic registration.
Since I've been introduced to DDMCMC for image segmentation, I have been thinking about the relationship between segmentation and recognition. Also, in my Advanced Perception course, we recently looked at some Borenstein/Ullman papers that incorporate segmentation and recognition into one framework (this resulted in a few more ideas). Here are some short ideas about segmentation:
How is the problem of segmentation usually posed? Given an image, produce a partition of the image into K disjoint regions. If one wants to only use the image data given with no object-level assumptions, then one can only proceed to find the maximum likelihood segmentation. However, such a segmentation will have a very large variance (and a small bias) because there are many different ways of 'grouping' local image structures together.
Fortunately, one can be Bayesian and relate the 'seemingly independent' problems of segmenting different images by utilizing a prior over image regions. When employing a Bayesian Hierarchical model, one generally breaks down the problem into two stages: parameter estimation(training) and statistical inference(testing). Just like in the LDA model, parameter estimation is concerned with estimating the hyperparameters of the hierarchical model (and also finding the distributions over latent variables for each document in the training set) and inference is segmenting a novel image (by utilizing the parameters obtained in the training stage). By being Bayesian, one will introduce bias when segmenting a novel image (the bias will make the novel segmentation more like some of the segmentations that were obtained for the training corpus) and reduce variance. Isn't bias a good thing in this case? Don't we REALLY want a novel segmentation to be somehow related to other segmentations? Perhaps the only property about a segmentation engine that we care about is its object-level consistency across a wide number of images. We hope that: given a large enough training corpus that captures large variability in pose and appearance for a large number of objects, the 'semantic'-segmentation that is desired will be the one that is approximated with our hierarchical model. A latent topic-based segmentation engine would additionaly provide a registration across image features via the latent topic space. In other words, semantically equivalent image primitives would be near each other in some high dimensional latent-topic parameter space.
The new question should be: How can we learn to segment novel images given a corpus of images that are somehow related? Under this view, a segmentation of a novel image is a k-way parition of an image AND the latent topic distributions associated with each segment (registration of segments across images). Remember, object tracking is temporal registration and object recognition is semantic registration.
Subscribe to:
Posts (Atom)